[SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork #32015
Conversation
|
Note that I tested subset of benchmarks, verified that it works, and now I am waiting for the final results of running all benchmarks: |
716e52b to
588d8c7
Compare
|
BTW, I will document this in https://spark.apache.org/developer-tools.html, and add the link into our docs (and probably in GItHub PR template?) |
588d8c7 to
0e2f439
Compare
|
It seems we can't run |
|
Yeah, good point. I will make it separate for now. |
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
Cool, it looks useful. |
0e2f439 to
e8a996f
Compare
|
GA is unstable now (https://www.githubstatus.com/). I will retrigger the full benchmarks tomorrow .. |
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
core/src/test/scala/org/apache/spark/benchmark/Benchmarks.scala
Outdated
Show resolved
Hide resolved
d9f9aae to
60d3f0e
Compare
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
| num-splits: | ||
| description: 'Number of job splits' | ||
| required: true | ||
| default: '1' |
There was a problem hiding this comment.
I had to add this parameter because GitHub Actions' limits job's timeout as 6 hours (workflow is 72 hours), and sequential running of benchmarks takes up to 50 hours. In this way, it runs the benchmarks in parallel so I think it's okay .. although it might expose too many parameters to control.
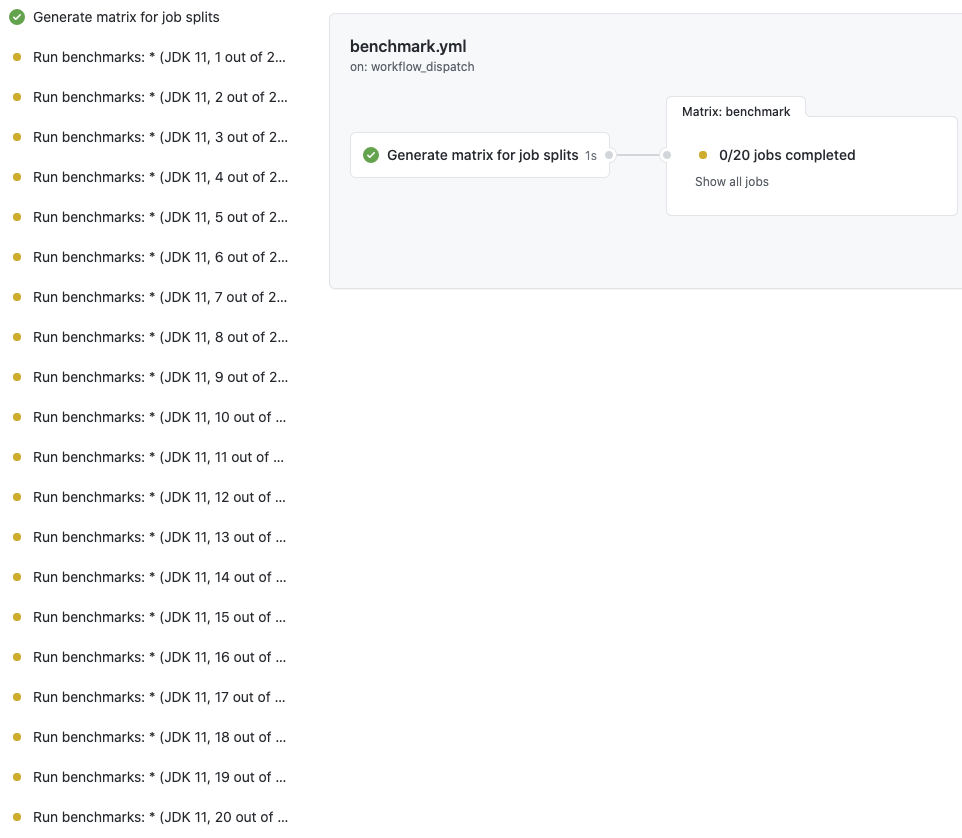
For example, I am now running all benchmarks in 20 splits (with JDK 11) at here:
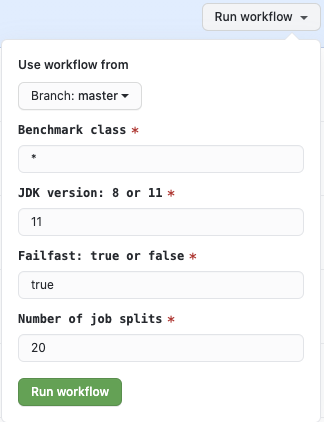
which results in 20 jobs that runs benchmarks in parallel (hashed by 20)
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
60a349e to
e6beeb5
Compare
| jsonInDS(50 * 1000 * 1000, numIters) | ||
| jsonInFile(50 * 1000 * 1000, numIters) | ||
| datetimeBenchmark(rowsNum = 10 * 1000 * 1000, numIters) | ||
| schemaInferring(5 * 1000 * 1000, numIters) |
There was a problem hiding this comment.
@MaxGekk I had to reduce the size here. Otherwise GA job dies with complaining no disk space
There was a problem hiding this comment.
With this, all benchmarks should pass now .. I will wait for the results before merging it in.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #136859 has finished for PR 32015 at commit
|
|
It's all passed: I am merging this to master. Thank you all for reviews and approvals |
|
Merged to master. |
…GitHub Actions machines ### What changes were proposed in this pull request? #32015 added a way to run benchmarks much more easily in the same GitHub Actions build. This PR updates the benchmark results by using the way. **NOTE** that looks like GitHub Actions use four types of CPU given my observations: - Intel(R) Xeon(R) Platinum 8171M CPU 2.60GHz - Intel(R) Xeon(R) CPU E5-2673 v4 2.30GHz - Intel(R) Xeon(R) CPU E5-2673 v3 2.40GHz - Intel(R) Xeon(R) Platinum 8272CL CPU 2.60GHz Given my quick research, seems like they perform roughly similarly:  I couldn't find enough information about Intel(R) Xeon(R) Platinum 8272CL CPU 2.60GHz but the performance seems roughly similar given the numbers. So shouldn't be a big deal especially given that this way is much easier, encourages contributors to run more and guarantee the same number of cores and same memory with the same softwares. ### Why are the changes needed? To have a base line of the benchmarks accordingly. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? It was generated from: - [Run benchmarks: * (JDK 11)](https://github.com/HyukjinKwon/spark/actions/runs/713575465) - [Run benchmarks: * (JDK 8)](https://github.com/HyukjinKwon/spark/actions/runs/713154337) Closes #32044 from HyukjinKwon/SPARK-34950. Authored-by: HyukjinKwon <[email protected]> Signed-off-by: Max Gekk <[email protected]>
{kind=link}
What changes were proposed in this pull request?
This PR proposes to add a workflow that allows developers to run benchmarks and download the results files. After this PR, developers can run benchmarks in GitHub Actions in their fork.
Why are the changes needed?
Does this PR introduce any user-facing change?
No, dev-only.
How was this patch tested?
Manually tested in HyukjinKwon#31.
Entire benchmarks are being run as below:
How do developers use it in their fork?
Go to Actions in your fork, and click "Run benchmarks"
Run the benchmarks with JDK 8 or 11 with benchmark classes to run. Glob pattern is supported just like
testOnlyin SBTAfter finishing the jobs, the benchmark results are available on the top in the underlying workflow:
After downloading it, unzip and untar at Spark git root directory:
Check the results: