[SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork #32015
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,99 @@ | ||
| name: Run benchmarks | ||
|
|
||
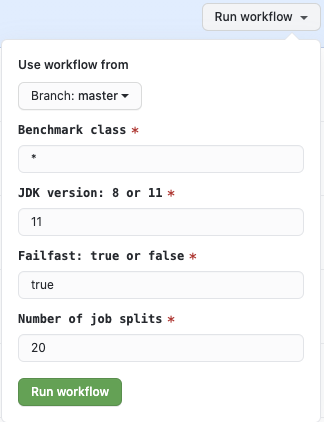
| on: | ||
| workflow_dispatch: | ||
| inputs: | ||
| class: | ||
| description: 'Benchmark class' | ||
| required: true | ||
| default: '*' | ||
| jdk: | ||
| description: 'JDK version: 8 or 11' | ||
| required: true | ||
| default: '8' | ||
HyukjinKwon marked this conversation as resolved.
Outdated
Show resolved
Hide resolved
|
||
| failfast: | ||
| description: 'Failfast: true or false' | ||
| required: true | ||
| default: 'true' | ||
| num-splits: | ||
| description: 'Number of job splits' | ||
| required: true | ||
| default: '1' | ||
|
Member
Author
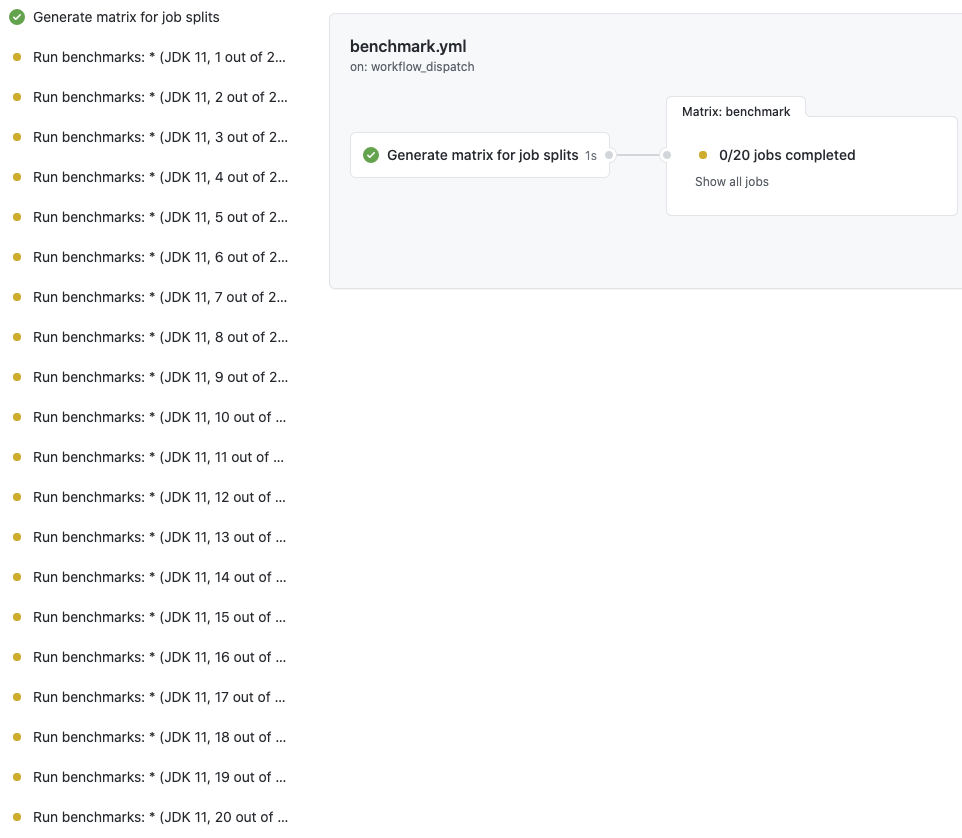
There was a problem hiding this comment. I had to add this parameter because GitHub Actions' limits job's timeout as 6 hours (workflow is 72 hours), and sequential running of benchmarks takes up to 50 hours. In this way, it runs the benchmarks in parallel so I think it's okay .. although it might expose too many parameters to control. For example, I am now running all benchmarks in 20 splits (with JDK 11) at here:
which results in 20 jobs that runs benchmarks in parallel (hashed by 20)
|
||
|
|
||
| jobs: | ||
| matrix-gen: | ||
| name: Generate matrix for job splits | ||
| runs-on: ubuntu-20.04 | ||
| outputs: | ||
| matrix: ${{ steps.set-matrix.outputs.matrix }} | ||
| env: | ||
| SPARK_BENCHMARK_NUM_SPLITS: ${{ github.event.inputs.num-splits }} | ||
| steps: | ||
| - name: Generate matrix | ||
| id: set-matrix | ||
| run: echo "::set-output name=matrix::["`seq -s, 1 $SPARK_BENCHMARK_NUM_SPLITS`"]" | ||
|
|
||
| benchmark: | ||
| name: "Run benchmarks: ${{ github.event.inputs.class }} (JDK ${{ github.event.inputs.jdk }}, ${{ matrix.split }} out of ${{ github.event.inputs.num-splits }} splits)" | ||
| needs: matrix-gen | ||
| # Ubuntu 20.04 is the latest LTS. The next LTS is 22.04. | ||
| runs-on: ubuntu-20.04 | ||
| strategy: | ||
| fail-fast: false | ||
| matrix: | ||
| split: ${{fromJSON(needs.matrix-gen.outputs.matrix)}} | ||
| env: | ||
| SPARK_BENCHMARK_FAILFAST: ${{ github.event.inputs.failfast }} | ||
| SPARK_BENCHMARK_NUM_SPLITS: ${{ github.event.inputs.num-splits }} | ||
| SPARK_BENCHMARK_CUR_SPLIT: ${{ matrix.split }} | ||
| SPARK_GENERATE_BENCHMARK_FILES: 1 | ||
| steps: | ||
| - name: Checkout Spark repository | ||
| uses: actions/checkout@v2 | ||
| # In order to get diff files | ||
| with: | ||
| fetch-depth: 0 | ||
| - name: Cache Scala, SBT and Maven | ||
| uses: actions/cache@v2 | ||
| with: | ||
| path: | | ||
| build/apache-maven-* | ||
| build/scala-* | ||
| build/*.jar | ||
| ~/.sbt | ||
| key: build-${{ hashFiles('**/pom.xml', 'project/build.properties', 'build/mvn', 'build/sbt', 'build/sbt-launch-lib.bash', 'build/spark-build-info') }} | ||
| restore-keys: | | ||
| build- | ||
| - name: Cache Coursier local repository | ||
| uses: actions/cache@v2 | ||
| with: | ||
| path: ~/.cache/coursier | ||
| key: benchmark-coursier-${{ github.event.inputs.jdk }}-${{ hashFiles('**/pom.xml', '**/plugins.sbt') }} | ||
| restore-keys: | | ||
| benchmark-coursier-${{ github.event.inputs.jdk }} | ||
| - name: Install Java ${{ github.event.inputs.jdk }} | ||
| uses: actions/setup-java@v1 | ||
| with: | ||
| java-version: ${{ github.event.inputs.jdk }} | ||
| - name: Run benchmarks | ||
| run: | | ||
| ./build/sbt -Pyarn -Pmesos -Pkubernetes -Phive -Phive-thriftserver -Phadoop-cloud -Pkinesis-asl -Pspark-ganglia-lgpl test:package | ||
HyukjinKwon marked this conversation as resolved.
Outdated
Show resolved
Hide resolved
|
||
| # Make less noisy | ||
| cp conf/log4j.properties.template conf/log4j.properties | ||
| sed -i 's/log4j.rootCategory=INFO, console/log4j.rootCategory=WARN, console/g' conf/log4j.properties | ||
| # In benchmark, we use local as master so set driver memory only. Note that GitHub Actions has 7 GB memory limit. | ||
| bin/spark-submit \ | ||
| --driver-memory 6g --class org.apache.spark.benchmark.Benchmarks \ | ||
| --jars "`find . -name '*-SNAPSHOT-tests.jar' -o -name '*avro*-SNAPSHOT.jar' | paste -sd ',' -`" \ | ||
| "`find . -name 'spark-core*-SNAPSHOT-tests.jar'`" \ | ||
| "${{ github.event.inputs.class }}" | ||
| # To keep the directory structure and file permissions, tar them | ||
| # See also https://github.com/actions/upload-artifact#maintaining-file-permissions-and-case-sensitive-files | ||
| echo "Preparing the benchmark results:" | ||
| tar -cvf benchmark-results-${{ github.event.inputs.jdk }}.tar `git diff --name-only` | ||
| - name: Upload benchmark results | ||
| uses: actions/upload-artifact@v2 | ||
| with: | ||
| name: benchmark-results-${{ github.event.inputs.jdk }}-${{ matrix.split }} | ||
| path: benchmark-results-${{ github.event.inputs.jdk }}.tar | ||
|
|
||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -519,16 +519,16 @@ object JsonBenchmark extends SqlBasedBenchmark { | |
| override def runBenchmarkSuite(mainArgs: Array[String]): Unit = { | ||
| val numIters = 3 | ||
| runBenchmark("Benchmark for performance of JSON parsing") { | ||
| schemaInferring(5 * 1000 * 1000, numIters) | ||
|
Member
Author
There was a problem hiding this comment. @MaxGekk I had to reduce the size here. Otherwise GA job dies with complaining no disk space
Member
Author
There was a problem hiding this comment. With this, all benchmarks should pass now .. I will wait for the results before merging it in. |
||
| countShortColumn(5 * 1000 * 1000, numIters) | ||
| countWideColumn(1000 * 1000, numIters) | ||
| countWideRow(50 * 1000, numIters) | ||
| selectSubsetOfColumns(1000 * 1000, numIters) | ||
| jsonParserCreation(1000 * 1000, numIters) | ||
| jsonFunctions(1000 * 1000, numIters) | ||
| jsonInDS(5 * 1000 * 1000, numIters) | ||
| jsonInFile(5 * 1000 * 1000, numIters) | ||
| datetimeBenchmark(rowsNum = 1000 * 1000, numIters) | ||
| // Benchmark pushdown filters that refer to top-level columns. | ||
| // TODO (SPARK-32325): Add benchmarks for filters with nested column attributes. | ||
| filtersPushdownBenchmark(rowsNum = 100 * 1000, numIters) | ||
|
|
||
Uh oh!
There was an error while loading. Please reload this page.