O Trabalho foi desenvolvido com a finalidade de otimizar o tempo de execução das operações de carregamento e processamento de dados do plugin Smart-Map do QGIS. Repositório oficial do plugin.
O Smart-Map é um plugin do QGIS, software para geração de mapas, que possibilita a interpolação de atributos do solo através do método geoestatístico Krigagem Ordinária e do algoritmo de Machine Learning Support Vector Machines. Porém, o app possui algumas limitações em relação ao número de pontos amostrados e tempo de execução.
Dessa forma, pretendeu-se otimizar a performance da ferramenta na duração do processamento e na quantidade de dadods a serem utilizados na realização das operações. As principais mudanças feitas na versão original foram:
- Troca da variação de Validação cruzada utilizada, antes Leave-One-Out, com as alterações a K-Fold;
- Alteração de códigos menos eficientes em termos de carregamento por técnicas mais atuais.
Com essas melhorias, observou-se um aumento significativo na velocidade de execução das funcionalidades do plugin, bem como o melhoramento do limite de dados usados para realizar as operações internas do app, na versão original 5.000 registros, com as atualizações, de acordo com as configurações do sistema computacional usados, até 50.000.
- Python: Linguagem de programação utilizada para o desenvolvimento original da aplicação.
- Pandas: Biblioteca do Python muito utilizada para carregamento de dados.
- Scikit-Learn: Biblioteca amplamente utilizada para lidar com processos que envolvam Machine Learning.
- Visual Studio Code: IDE escolhida para o desenvolvimento da aplicação.
- Linux (Ubuntu): Sistema operacional utilizado para testar e desenvolver o projeto. Versão usada: 22.0.4.
Especificações da máquina utilizada para desenvolvimento
Computador equipado com:
processador de 12th Gen Intel® Core™ i5-12450H × 12,20GB de RAM,SSD de 500GB.
Nesse método, os dados são divididos separados em k subconjuntos, ou folds. O modelo é treinado k vezes, e em cada uma delas utilizando k-1 folds para treino e o fold restante para teste. Dessa forma, existente um controle maior do número de treinos do algoritmo, o que contribui drasticamente para a redução do uso de memória do sistema.

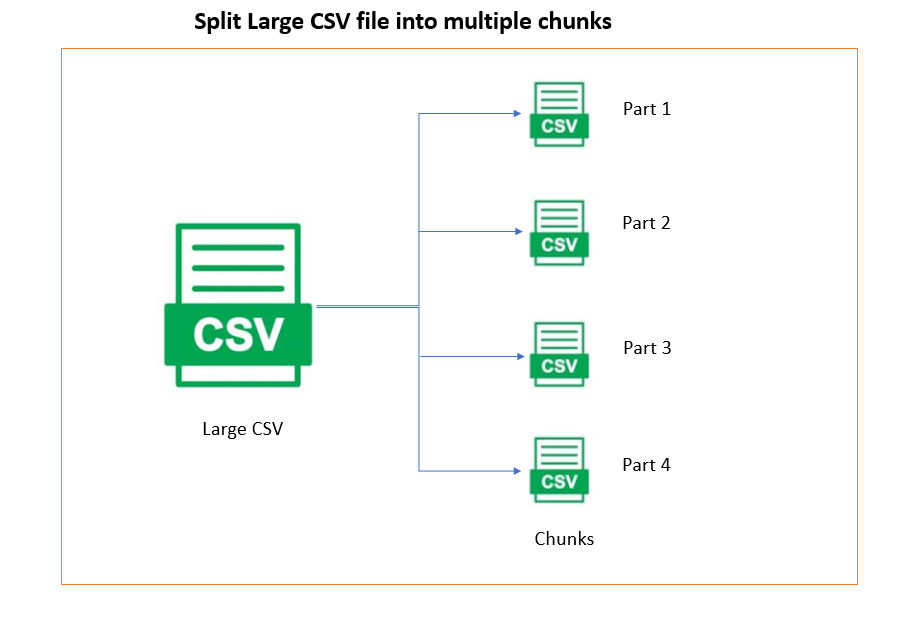
O conceito de paginação no contexto de grandes conjuntos de dados envolve dividir os dados em partes menores e mais gerenciáveis, chamadas de páginas ou blocos (chunks). Essa técnica pode ser especialmente útil, pois processar blocos menores de registros é mais rápido do que carregar o dataset por completo, além de reduzir a carga computacional no sistema.
This project is free; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3 of the License, or (at your option) any later version.
PEREIRA,Gustavo Willam.Ferramentas computacionais para suporte a decisão no mapeamento de atributos do solo. 2021. Tese – Universidade Federal de Viçosa, Viçosa, 2021. Disponível em:https://locus.ufv.br//handle/123456789/29872. Acesso em: 22 ago.2024.
ORACLE. What is Machine Learning?. Disponível em: https://www.oracle.com/br/artificial-intelligence/machine-learning/what-is-machine-learning/. Acesso em: 22 ago. 2024.
REMÍGIO, M. Máquinas de vetores de suporte (SVM). Medium, 2020. Disponível em: https://medium.com/@msremigio/m%C3%A1quinas-de-vetores-de-suporte-svm-77bb114d02fc. Acesso em: 22 ago. 2024.
ESCOVEDO, T.; KOSHIYAMA, A. S. Introdução a Data Science — Algoritmos de Machine Learning e métodos de análise. São Paulo: Ed. Casa do Código, 2020.
ESCOVEDO, T. Machine Learning: conceitos e modelos. Medium, 2020. Disponível em: https://tatianaesc.medium.com/machine-learning-conceitos-e-modelos-f0373bf4f445. Acesso em: 22 ago. 2024.
ANALYTICS VIDHYA. Support Vector Machines (SVM) – A Complete Guide for Beginners. 2021. Disponível em: https://www.analyticsvidhya.com/blog/2021/10/support-vector-machinessvm-a-complete-guide-for-beginners/. Acesso em: 22 ago. 2024.
MEDIUM. The Kernel Trick. Medium, 2020. Disponível em: https://towardsdatascience.com/the-kernel-trick-c98cdbcaeb3f. Acesso em: 22 ago. 2024.
ZHU, X. What is the Kernel Trick? Why is it Important?. Medium, 2021. Disponível em: https://medium.com/@zxr.nju/what-is-the-kernel-trick-why-is-it-important-98a98db0961d. Acesso em: 22 ago. 2024.
STACKABUSE. Understanding SVM Hyperparameters. 2021. Disponível em: https://stackabuse.com/understanding-svm-hyperparameters/. Acesso em: 22 ago. 2024.
FARAMARZI, N. Support Vector Regressor: Theory and Coding Exercise in Python. Medium, 2020. Disponível em: https://medium.com/@niousha.rf/support-vector-regressor-theory-and-coding-exercise-in-python-ca6a7dfda927. Acesso em: 22 ago. 2024.
SCIKIT-LEARN. Cross-Validation. Disponível em: https://scikit-learn.org/stable/modules/cross_validation.html. Acesso em: 22 ago. 2024.
PATEL, B. Resampling Methods. Bijen Patel, 2022. Disponível em: https://www.bijenpatel.com/guide/islr/resampling-methods/. Acesso em: 22 ago. 2024.
WIKIPEDIA. Cross-validation (statistics). 2024. Disponível em: https://en.wikipedia.org/wiki/Cross-validation_(statistics). Acesso em: 22 ago. 2024.
TEAMCODE. A Step-by-Step Guide for Pagination in Python. Medium, 2023. Disponível em: https://medium.com/@teamcode20233/a-step-by-step-guide-for-pagination-in-python-f7da5f06767d. Acesso em: 22 ago. 2024.