On backpressure block #1902
On backpressure block #1902
Conversation
|
I definitely think this is useful. What I'd also like is some helpers to help you implement your own back pressure aware Observable. We've made an internal wrapper class for doing blocking back pressure Observables, similar to this, but we're not sure if that's the best approach. |
|
If you can express your computation in Iterable form, then you get backpressure for free. In one of the bug reports earlier, the person used Guava's AbstractIterable where you only need to implement a single method calculating the next value or signal completion. |
|
Great point David, would be good to have that suggestion in the wiki. On 27 November 2014 at 01:02, David Karnok [email protected] wrote:
|
|
Would it be a good idea to fail (emit |
|
If we could reliably detect the computation scheduler, but even if, what If the source emission jumps between the IO scheduler and the Computation scheduler due to serialization, and the scheduler is detected only after some time? |
That's easy enough to do.
I don't understand what role this plays. If the blocking was attempted in the IO Scheduler that's fine. If attempts on the Computation Scheduler, that's not okay. Blocking on the IO Scheduler would not cause the Computation thread to block since |
|
I guess you mean, for example, |
|
It can be done easier and cheaper with a simple ThreadLocal boolean and a static check. We want this anyways so we stop randomly scheduling and bouncing between threads. That's an optimization I'll be adding soon. Netty does similar and it's a big improvement. |
|
When I was experimenting with a balancing computation scheduler, I tried this ThreadLocal approach, but its internal HashMap lookup takes some time. However, since we alread provide custom threads to the executor pool, we can identify the threads by their class after Thread.currentThread(). |
|
What time did you measure as an impact per operation? |
|
Here is what Netty does that may be worth us looking at if we want to pursue this route: https://github.com/netty/netty/blob/b72a05edb41a97017e9bd7877edcd2014a8d99d9/common/src/main/java/io/netty/util/concurrent/FastThreadLocal.java Sounds like they found the same thing as you did regarding its use of HashMap. |
|
It cost about 10-15 cycles (about 5ns per item on i7 920, 2ns on i7 4770) which seems small, but if the actual operation is fast, this may seem to slow down things. This is why I abandoned it back then because it lowered the perf numbers. I've tried benchmarking the difference between a threadlocal and a cast to the custom thread, but I don't fully trust the results: ThreadLocal: 3.3ns, Thread+cast: 0.8ns. public class ThreadTypeCost {
static final class MyThread extends Thread {
public int threadLocal = 1;
public MyThread(Runnable r) {
super(r);
}
}
static int f;
public static void main(String[] args) throws Exception {
ExecutorService exec = Executors.newFixedThreadPool(1, f -> {
MyThread t = new MyThread(f);
return t;
});
ThreadLocal<Boolean> tl = new ThreadLocal<Boolean>() {
@Override
public Boolean initialValue() {
return true;
}
};
int k = 10_000_000;
long n = System.nanoTime();
exec.submit(() -> {
for (int i = 0; i < k; i++) {
// Thread t = Thread.currentThread();
// if (t instanceof MyThread) {
// MyThread mt = (MyThread) t;
// f += mt.threadLocal;
// }
if (tl.get()) {
f++;
}
}
});
exec.shutdown();
exec.awaitTermination(1, TimeUnit.HOURS);
System.out.println(1d * (System.nanoTime() - n) / k);
}
} |
|
I think we should use JMH for this. I've read enough about why JMH was created and the problems with using nanoTime directly to mistrust basically all benchmarks now :-) |
|
Once we agree upon #1824 let's mark this as |
|
Okay. |
|
I added |
|
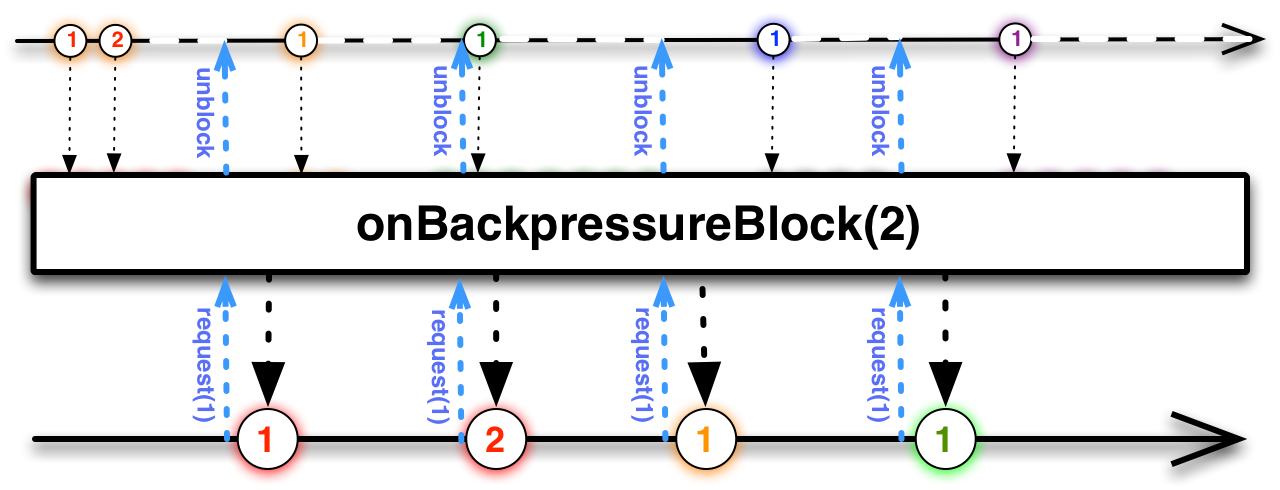
Does this diagram ( On Sat, Nov 29, 2014 at 1:52 PM, Ben Christensen [email protected]
David M. Gross |
{kind=link}
|
I'm not sure. These patterns are non-blocking: These patterns are blocking this latter may happen if the consumer runs on a different thread and is slowly draining. So if the consumer is slow or doesn't give enough permits, the queue will fill up and will block on the next over-capacity enqueue attempt. At this point, only the consumer running on another thread may unblock the producer by requesting more and then draining the queue until the queue becomes empty or the permits run out. |
After watching Ben's great JavaOne 2014 talk, I was wondering why there isn't a onBackpressureBlock, i.e., a strategy which blocks the producer thread.
On one hand, I can accept we don't want to encourage blocking operations, on the other hand, this operator may allow casual Observable.create() implementations to not worry about backpressure at the expense of blocking one Schedulers.io() thread.