PERF: Series.value_counts() in aggregation function is slower than collections.Counter() #49728
Description
Pandas version checks
-
I have checked that this issue has not already been reported.
-
I have confirmed this issue exists on the latest version of pandas.
-
I have confirmed this issue exists on the main branch of pandas.
Reproducible Example
Series.value_counts() are slower especially if it counts for a small size of iterable elements.
Case1: value_counts() for counting small iterable elements
The picture below is the result of simulation 1 where I compared the speed of counting values for Series.value_counts() and collections.Counter(). In this simulation, I measured time for counting iterables of variable sizes (

Source code for simulation 1:
@timing
def value_count_collections_x(n, sort=False):
x = np.random.randint(0, 1000, (n))
vc = Counter(x)
if sort:
vc = dict(sorted(vc.items(), key=lambda x: x[1], reverse=True))
return vc
@timing
def value_count_series_x(n, sort=False):
x = np.random.randint(0, 1000, (n))
vc = pd.Series(x).value_counts(sort=sort)
return vc
for _ in range(5):
for n in [10, 100, 1000, 10_000, 100_000, 1_000_000, 10_000_000]:
value_count_collections_x(n)
value_count_series_x(n)Case2: repeatedly calls value_counts() in aggregation functions
That also comes to be issue when using in aggregation functions. I run another simulation to compare the execution time for Series.value_counts() and collections.Counter() 2. This time I used counting methods in an aggregate function. It also shows Series.value_counts() is 5 times slower than collections.Counter() method.
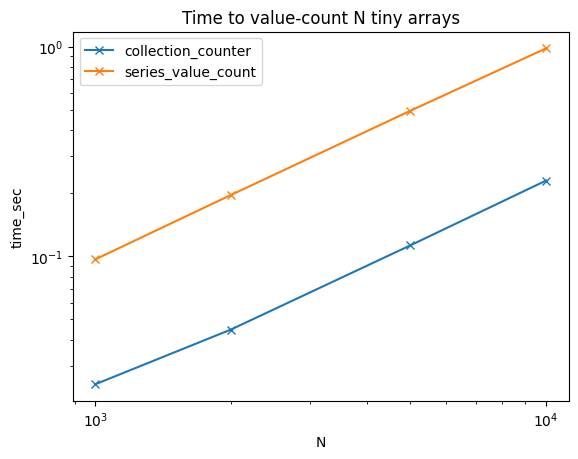
source code for simulation 2:
@timing
def collection_counter(n, sort=False):
def agg_top20(x):
counter = Counter(x)
top20 = dict(counter.most_common(20)).keys()
return " ".join(map(str, top20))
df = pd.DataFrame(
pd.DataFrame(np.random.randint(0, 1000, (n, 100))).stack().reset_index()
)
return df.groupby("level_0")[0].agg(agg_top20)
@timing
def series_value_count(n, sort=False):
def agg_top20(x):
counter = x.value_counts()
top20 = counter.iloc[:20].index
return " ".join(map(str, top20))
df = pd.DataFrame(
pd.DataFrame(np.random.randint(0, 1000, (n, 100))).stack().reset_index()
)
return df.groupby("level_0")[0].agg(agg_top20)
for _ in range(5):
for n in [1000, 2_000, 5_000, 10_000]:
collection_counter(n)
series_value_count(n)Is this an expected performance for value_counts()? If it isn't performance improvement should be cared.
Installed Versions
pandas : 1.5.1
numpy : 1.23.4
pytz : 2022.1
dateutil : 2.8.2
setuptools : 59.6.0
pip : 22.0.2
Cython : None
pytest : None
hypothesis : None
sphinx : None
blosc : None
feather : None
xlsxwriter : None
lxml.etree : None
html5lib : None
pymysql : None
psycopg2 : None
jinja2 : 3.0.3
IPython : 8.6.0
pandas_datareader: None
bs4 : 4.11.1
bottleneck : None
brotli : None
fastparquet : 0.8.3
fsspec : 2022.10.0
gcsfs : None
matplotlib : 3.6.0
numba : None
numexpr : None
odfpy : None
openpyxl : None
pandas_gbq : None
pyarrow : None
pyreadstat : None
pyxlsb : None
s3fs : None
scipy : None
snappy : None
sqlalchemy : None
tables : None
tabulate : None
xarray : None
xlrd : None
xlwt : None
zstandard : None
tzdata : None
Prior Performance
No response