docs: improve llama.cpp install instructions. #720
Merged
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
cc: @gary149 - can I get your blessings to merge this PR, too, please? 🙏 |
julien-c
reviewed
May 30, 2024
julien-c
reviewed
May 30, 2024
julien-c
approved these changes
May 30, 2024
Co-authored-by: Julien Chaumond <[email protected]>
|
Sounds good to me, I will wait for @pcuenca to confirm that it looks good to him, too (since it's slightly deviating from his original idea) before merging. |
pcuenca
approved these changes
May 30, 2024
|
I don't know why the E2E error fails, will wait for @coyotte508's guidance |
osanseviero
approved these changes
May 30, 2024
mishig25
pushed a commit
that referenced
this pull request
Jun 5, 2024
follow up to #720 just like we show two snippets for transformers (pipeline & automodel) (example [here](https://huggingface.co/mistralai/Codestral-22B-v0.1?library=transformers)) 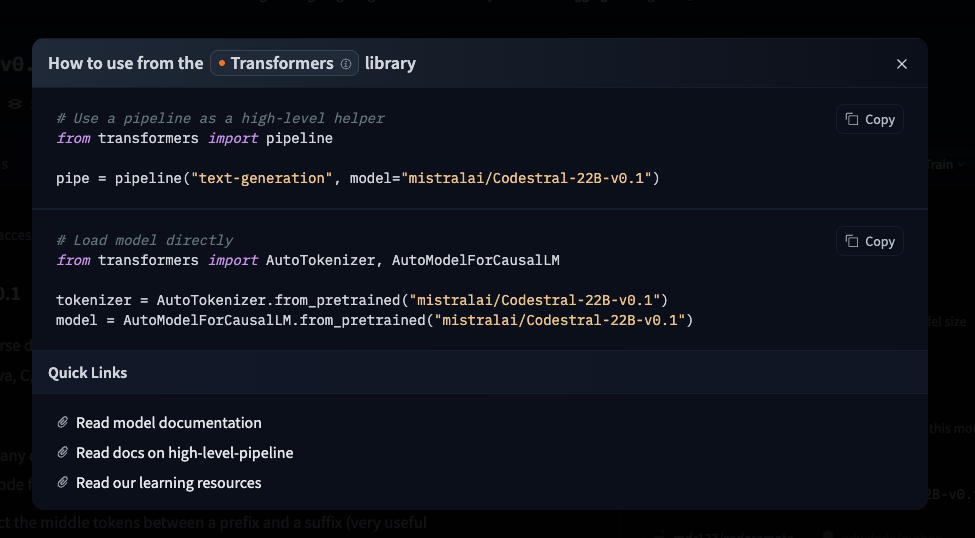 we should show the two options for llama.cpp clearly as well. The two options are: installing from brew and installing from source  --------- Co-authored-by: Victor Muštar <[email protected]>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Does two things:
-mto--hf-filethis would make sure that the models are cached