-
Notifications
You must be signed in to change notification settings - Fork 6.1k
Music Spectrogram diffusion pipeline #1044
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Merged
patrickvonplaten
merged 159 commits into
huggingface:main
from
kashif:spectrogram-diffusion
Mar 23, 2023
Merged
Changes from all commits
Commits
Show all changes
159 commits
Select commit
Hold shift + click to select a range
f85d908
initial TokenEncoder and ContinuousEncoder
kashif e025410
initial modules
kashif e88dc6f
added ContinuousContextTransformer
kashif c9dd1dd
Merge branch 'main' into spectrogram-diffusion
kashif 59e2111
fix copy paste error
kashif ab82923
use numpy for get_sequence_length
kashif cdc6ec7
initial terminal relative positional encodings
kashif c55fb5b
fix weights keys
kashif af67374
fix assert
kashif ef43fe0
cross attend style: concat encodings
kashif 33755df
Merge branch 'main' into spectrogram-diffusion
kashif 6de0cfb
make style
kashif 1068282
Merge branch 'main' into spectrogram-diffusion
kashif 5546c12
concat once
kashif 8b32df3
fix formatting
kashif c69a3b9
Initial SpectrogramPipeline
kashif f7254db
fix input_tokens
kashif 133d155
make style
kashif aa2323f
added mel output
kashif c154878
ignore weights for config
kashif 63f69b6
move mel to numpy
kashif 9808d06
import pipeline
kashif 49d95c0
fix class names and import
kashif ce4a658
moved models to models folder
kashif b3caf35
import ContinuousContextTransformer and SpectrogramDiffusionPipeline
kashif 593e2aa
initial spec diffusion converstion script
kashif c707799
renamed config to t5config
kashif 55bb6dd
added weight loading
kashif 7cb32d7
use arguments instead of t5config
kashif 0251747
broadcast noise time to batch dim
kashif 8a54f88
fix call
kashif b6373b8
added scale_to_features
kashif 5fb437d
fix weights
kashif 5591f21
transpose laynorm weight
kashif 21b7ea2
scale is a vector
kashif 87ee8a3
scale the query outputs
kashif 6deafab
added comment
kashif 8830c2b
undo scaling
kashif 3b9e822
undo depth_scaling
kashif 9328701
inital get_extended_attention_mask
kashif f86a785
attention_mask is none in self-attention
kashif 9905492
cleanup
kashif f439e5b
manually invert attention
kashif dd5dc10
nn.linear need bias=False
kashif d987df0
added T5LayerFFCond
kashif 428fae9
remove to fix conflict
kashif 9b1f8d3
Merge branch 'main' into spectrogram-diffusion
kashif 670331e
make style and dummy
kashif 70c5637
Merge branch 'main' into spectrogram-diffusion
kashif f98beeb
remove unsed variables
kashif 37735c0
remove predict_epsilon
kashif f9217a7
Move accelerate to a soft-dependency (#1134)
patrickvonplaten ff51d45
fix order
kashif 4a215dd
added initial midi to note token data pipeline
kashif d8544cb
added int to int tokenizer
kashif 5f62843
remove duplicate
kashif 505e78a
added logic for segments
kashif 52f7896
add melgan to pipeline
kashif 1e26776
move autoregressive gen into pipeline
kashif a643c8b
added note_representation_processor_chain
kashif 202b810
fix dtypes
kashif 085d766
remove immutabledict req
kashif 3edc9e1
initial doc
kashif 3025973
Merge branch 'main' into spectrogram-diffusion
kashif 5472ef5
use np.where
kashif 41e56f0
Merge branch 'main' into spectrogram-diffusion
kashif 87b5914
require note_seq
kashif cf24a45
fix typo
kashif 6d48ef9
Merge branch 'main' into spectrogram-diffusion
kashif 00465c4
update dependency
kashif cd097b4
added note-seq to test
kashif 04ac770
added is_note_seq_available
kashif 2afaf27
fix import
kashif d4c167c
Merge branch 'main' into spectrogram-diffusion
kashif 8f8371e
Merge branch 'main' into spectrogram-diffusion
kashif 3acb123
added toc
kashif b9d0842
added example usage
kashif f3b4ad4
undo for now
kashif 7ab039f
Merge branch 'main' into spectrogram-diffusion
kashif 50908b8
moved docs
kashif 79b278d
Merge branch 'main' into spectrogram-diffusion
kashif cfd0c7f
fix merge
kashif 71ed0dc
fix imports
kashif 43783d1
Merge branch 'main' into spectrogram-diffusion
kashif e4af28e
predict first segment
kashif 8f74e27
avoid un-needed copy to and from cpu
kashif bbddffa
make style
kashif da82d61
Merge branch 'main' into spectrogram-diffusion
kashif 908d8ac
Copyright
kashif e3c028d
Merge branch 'main' into spectrogram-diffusion
kashif 92b20ba
Merge branch 'main' into spectrogram-diffusion
kashif 9e57320
fix style
kashif bf2c9f4
Merge branch 'main' into spectrogram-diffusion
kashif 7509478
Merge branch 'main' into spectrogram-diffusion
patrickvonplaten e8b73d0
add test and fix inference steps
patrickvonplaten 7dda059
remove bogus files
patrickvonplaten 19e6013
reorder models
patrickvonplaten 0a1b02b
up
patrickvonplaten 17d0edf
remove transformers dependency
patrickvonplaten 658080c
make work with diffusers cross attention
patrickvonplaten 49fbce7
clean more
patrickvonplaten fa2d918
remove @
patrickvonplaten dc2a226
improve further
patrickvonplaten f9b9641
up
patrickvonplaten 1bd68f2
uP
patrickvonplaten e58ac32
Merge branch 'main' into spectrogram-diffusion
kashif 25cb927
Apply suggestions from code review
patrickvonplaten 59101b5
Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusi…
patrickvonplaten 7e0e8ea
Merge branch 'main' into spectrogram-diffusion
kashif bc83fb3
loop over all tokens
kashif 783f89e
make style
kashif 5584ab3
Added a section on the model
kashif 46ad2c7
fix formatting
kashif a9cafb7
grammer
kashif 3f1bb13
formatting
kashif ff5e135
make fix-copies
kashif 07f5429
Update src/diffusers/pipelines/__init__.py
kashif bae1eda
Update src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectro…
kashif adf1e6e
added callback ad optional ionnx
kashif 1e78af9
do not squeeze batch dim
kashif 098f1a2
clean up more
patrickvonplaten fa77427
upload
patrickvonplaten 56b7101
Merge branch 'main' into spectrogram-diffusion
kashif 40a7f78
convert jax to nnumpy
kashif 14b1956
make style
kashif 40e90f0
fix warning
kashif a883b3b
Merge branch 'main' into spectrogram-diffusion
patrickvonplaten 819705c
make fix-copies
kashif de162e5
Merge branch 'main' into spectrogram-diffusion
kashif d6285a0
Merge branch 'main' into spectrogram-diffusion
patrickvonplaten a2725a2
fix warning
kashif 0b850f3
add initial fast tests
kashif d326591
add initial pipeline_params
kashif dffad61
eval mode due to dropout
kashif 78397e4
skip batch tests as pipeline runs on a single file
kashif 4908b05
make style
kashif ad0c500
Merge branch 'main' into spectrogram-diffusion
kashif 03c7ae5
fix relative path
kashif dfb3282
fix doc tests
kashif 2a38f76
Update src/diffusers/models/t5_film_transformer.py
kashif 96111b2
Update src/diffusers/models/t5_film_transformer.py
kashif f436adb
Merge branch 'main' into spectrogram-diffusion
kashif 17dbe1d
Update docs/source/en/api/pipelines/spectrogram_diffusion.mdx
kashif dd9f8ca
Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusi…
kashif 654c796
Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusi…
kashif 9a8a93d
Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusi…
kashif ebb8e9a
Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusi…
kashif 3a94476
add MidiProcessor
kashif 7c43be8
format
kashif 6dcd3f7
fix org
kashif 17b7481
Apply suggestions from code review
patrickvonplaten 458e7b7
Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusi…
patrickvonplaten 4f27f66
make style
kashif dc8280e
Merge branch 'main' into spectrogram-diffusion
kashif 76a28c1
pin protobuf to <4
kashif 7339d37
fix formatting
kashif f71b155
white space
kashif e5225a3
tensorboard needs protobuf
kashif 8abbd57
Merge branch 'main' into spectrogram-diffusion
kashif File filter
Filter by extension
Conversations
Failed to load comments.
Loading
Jump to
Jump to file
Failed to load files.
Loading
Diff view
Diff view
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,54 @@ | ||
| <!--Copyright 2023 The HuggingFace Team. All rights reserved. | ||
|
|
||
| Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with | ||
| the License. You may obtain a copy of the License at | ||
|
|
||
| http://www.apache.org/licenses/LICENSE-2.0 | ||
|
|
||
| Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on | ||
| an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | ||
| specific language governing permissions and limitations under the License. | ||
| --> | ||
|
|
||
| # Multi-instrument Music Synthesis with Spectrogram Diffusion | ||
|
|
||
| ## Overview | ||
|
|
||
| [Spectrogram Diffusion](https://arxiv.org/abs/2206.05408) by Curtis Hawthorne, Ian Simon, Adam Roberts, Neil Zeghidour, Josh Gardner, Ethan Manilow, and Jesse Engel. | ||
|
|
||
| An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes. | ||
|
|
||
| The original codebase of this implementation can be found at [magenta/music-spectrogram-diffusion](https://github.com/magenta/music-spectrogram-diffusion). | ||
|
|
||
| ## Model | ||
|
|
||
|  | ||
|
|
||
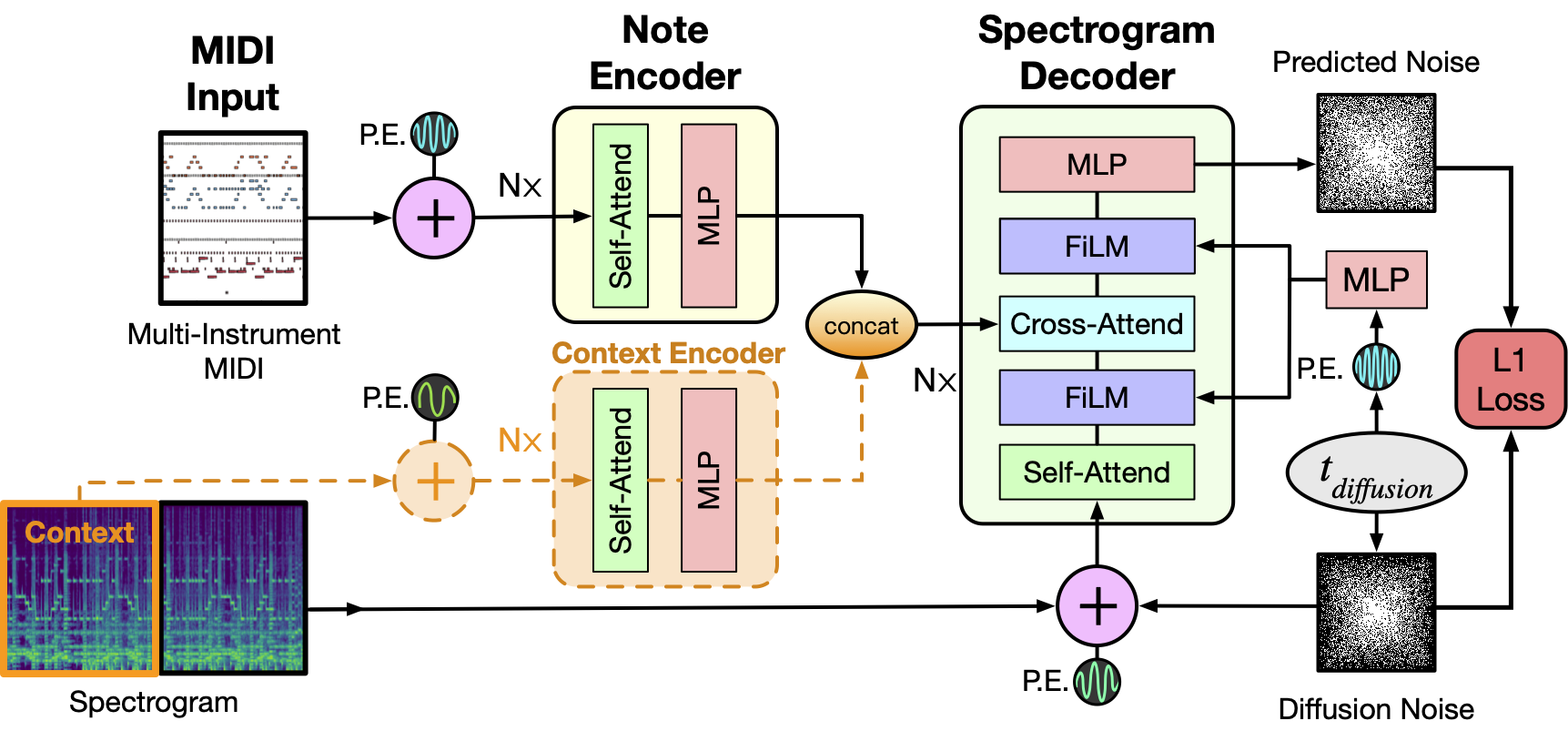
| As depicted above the model takes as input a MIDI file and tokenizes it into a sequence of 5 second intervals. Each tokenized interval then together with positional encodings is passed through the Note Encoder and its representation is concatenated with the previous window's generated spectrogram representation obtained via the Context Encoder. For the initial 5 second window this is set to zero. The resulting context is then used as conditioning to sample the denoised Spectrogram from the MIDI window and we concatenate this spectrogram to the final output as well as use it for the context of the next MIDI window. The process repeats till we have gone over all the MIDI inputs. Finally a MelGAN decoder converts the potentially long spectrogram to audio which is the final result of this pipeline. | ||
|
|
||
| ## Available Pipelines: | ||
|
|
||
| | Pipeline | Tasks | Colab | ||
| |---|---|:---:| | ||
| | [pipeline_spectrogram_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion) | *Unconditional Audio Generation* | - | | ||
|
|
||
|
|
||
| ## Example usage | ||
|
|
||
| ```python | ||
| from diffusers import SpectrogramDiffusionPipeline, MidiProcessor | ||
|
|
||
| pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion") | ||
| pipe = pipe.to("cuda") | ||
| processor = MidiProcessor() | ||
|
|
||
| # Download MIDI from: wget http://www.piano-midi.de/midis/beethoven/beethoven_hammerklavier_2.mid | ||
| output = pipe(processor("beethoven_hammerklavier_2.mid")) | ||
|
|
||
| audio = output.audios[0] | ||
| ``` | ||
|
|
||
| ## SpectrogramDiffusionPipeline | ||
| [[autodoc]] SpectrogramDiffusionPipeline | ||
| - all | ||
| - __call__ | ||
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,213 @@ | ||
| #!/usr/bin/env python3 | ||
| import argparse | ||
| import os | ||
|
|
||
| import jax as jnp | ||
| import numpy as onp | ||
| import torch | ||
| import torch.nn as nn | ||
| from music_spectrogram_diffusion import inference | ||
| from t5x import checkpoints | ||
|
|
||
| from diffusers import DDPMScheduler, OnnxRuntimeModel, SpectrogramDiffusionPipeline | ||
| from diffusers.pipelines.spectrogram_diffusion import SpectrogramContEncoder, SpectrogramNotesEncoder, T5FilmDecoder | ||
|
|
||
|
|
||
| MODEL = "base_with_context" | ||
|
|
||
|
|
||
| def load_notes_encoder(weights, model): | ||
| model.token_embedder.weight = nn.Parameter(torch.FloatTensor(weights["token_embedder"]["embedding"])) | ||
| model.position_encoding.weight = nn.Parameter( | ||
| torch.FloatTensor(weights["Embed_0"]["embedding"]), requires_grad=False | ||
| ) | ||
| for lyr_num, lyr in enumerate(model.encoders): | ||
| ly_weight = weights[f"layers_{lyr_num}"] | ||
| lyr.layer[0].layer_norm.weight = nn.Parameter( | ||
| torch.FloatTensor(ly_weight["pre_attention_layer_norm"]["scale"]) | ||
| ) | ||
|
|
||
| attention_weights = ly_weight["attention"] | ||
| lyr.layer[0].SelfAttention.q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T)) | ||
| lyr.layer[0].SelfAttention.k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T)) | ||
| lyr.layer[0].SelfAttention.v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T)) | ||
| lyr.layer[0].SelfAttention.o.weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T)) | ||
|
|
||
| lyr.layer[1].layer_norm.weight = nn.Parameter(torch.FloatTensor(ly_weight["pre_mlp_layer_norm"]["scale"])) | ||
|
|
||
| lyr.layer[1].DenseReluDense.wi_0.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_0"]["kernel"].T)) | ||
| lyr.layer[1].DenseReluDense.wi_1.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_1"]["kernel"].T)) | ||
| lyr.layer[1].DenseReluDense.wo.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wo"]["kernel"].T)) | ||
|
|
||
| model.layer_norm.weight = nn.Parameter(torch.FloatTensor(weights["encoder_norm"]["scale"])) | ||
| return model | ||
|
|
||
|
|
||
| def load_continuous_encoder(weights, model): | ||
| model.input_proj.weight = nn.Parameter(torch.FloatTensor(weights["input_proj"]["kernel"].T)) | ||
|
|
||
| model.position_encoding.weight = nn.Parameter( | ||
| torch.FloatTensor(weights["Embed_0"]["embedding"]), requires_grad=False | ||
| ) | ||
|
|
||
| for lyr_num, lyr in enumerate(model.encoders): | ||
| ly_weight = weights[f"layers_{lyr_num}"] | ||
| attention_weights = ly_weight["attention"] | ||
|
|
||
| lyr.layer[0].SelfAttention.q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T)) | ||
| lyr.layer[0].SelfAttention.k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T)) | ||
| lyr.layer[0].SelfAttention.v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T)) | ||
| lyr.layer[0].SelfAttention.o.weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T)) | ||
| lyr.layer[0].layer_norm.weight = nn.Parameter( | ||
| torch.FloatTensor(ly_weight["pre_attention_layer_norm"]["scale"]) | ||
| ) | ||
|
|
||
| lyr.layer[1].DenseReluDense.wi_0.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_0"]["kernel"].T)) | ||
| lyr.layer[1].DenseReluDense.wi_1.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_1"]["kernel"].T)) | ||
| lyr.layer[1].DenseReluDense.wo.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wo"]["kernel"].T)) | ||
| lyr.layer[1].layer_norm.weight = nn.Parameter(torch.FloatTensor(ly_weight["pre_mlp_layer_norm"]["scale"])) | ||
|
|
||
| model.layer_norm.weight = nn.Parameter(torch.FloatTensor(weights["encoder_norm"]["scale"])) | ||
|
|
||
| return model | ||
|
|
||
|
|
||
| def load_decoder(weights, model): | ||
| model.conditioning_emb[0].weight = nn.Parameter(torch.FloatTensor(weights["time_emb_dense0"]["kernel"].T)) | ||
| model.conditioning_emb[2].weight = nn.Parameter(torch.FloatTensor(weights["time_emb_dense1"]["kernel"].T)) | ||
|
|
||
| model.position_encoding.weight = nn.Parameter( | ||
| torch.FloatTensor(weights["Embed_0"]["embedding"]), requires_grad=False | ||
| ) | ||
|
|
||
| model.continuous_inputs_projection.weight = nn.Parameter( | ||
| torch.FloatTensor(weights["continuous_inputs_projection"]["kernel"].T) | ||
| ) | ||
|
|
||
| for lyr_num, lyr in enumerate(model.decoders): | ||
| ly_weight = weights[f"layers_{lyr_num}"] | ||
| lyr.layer[0].layer_norm.weight = nn.Parameter( | ||
| torch.FloatTensor(ly_weight["pre_self_attention_layer_norm"]["scale"]) | ||
| ) | ||
|
|
||
| lyr.layer[0].FiLMLayer.scale_bias.weight = nn.Parameter( | ||
| torch.FloatTensor(ly_weight["FiLMLayer_0"]["DenseGeneral_0"]["kernel"].T) | ||
| ) | ||
|
|
||
| attention_weights = ly_weight["self_attention"] | ||
| lyr.layer[0].attention.to_q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T)) | ||
| lyr.layer[0].attention.to_k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T)) | ||
| lyr.layer[0].attention.to_v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T)) | ||
| lyr.layer[0].attention.to_out[0].weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T)) | ||
|
|
||
| attention_weights = ly_weight["MultiHeadDotProductAttention_0"] | ||
| lyr.layer[1].attention.to_q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T)) | ||
| lyr.layer[1].attention.to_k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T)) | ||
| lyr.layer[1].attention.to_v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T)) | ||
| lyr.layer[1].attention.to_out[0].weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T)) | ||
| lyr.layer[1].layer_norm.weight = nn.Parameter( | ||
| torch.FloatTensor(ly_weight["pre_cross_attention_layer_norm"]["scale"]) | ||
| ) | ||
|
|
||
| lyr.layer[2].layer_norm.weight = nn.Parameter(torch.FloatTensor(ly_weight["pre_mlp_layer_norm"]["scale"])) | ||
| lyr.layer[2].film.scale_bias.weight = nn.Parameter( | ||
| torch.FloatTensor(ly_weight["FiLMLayer_1"]["DenseGeneral_0"]["kernel"].T) | ||
| ) | ||
| lyr.layer[2].DenseReluDense.wi_0.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_0"]["kernel"].T)) | ||
| lyr.layer[2].DenseReluDense.wi_1.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_1"]["kernel"].T)) | ||
| lyr.layer[2].DenseReluDense.wo.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wo"]["kernel"].T)) | ||
|
|
||
| model.decoder_norm.weight = nn.Parameter(torch.FloatTensor(weights["decoder_norm"]["scale"])) | ||
|
|
||
| model.spec_out.weight = nn.Parameter(torch.FloatTensor(weights["spec_out_dense"]["kernel"].T)) | ||
|
|
||
| return model | ||
|
|
||
|
|
||
| def main(args): | ||
| t5_checkpoint = checkpoints.load_t5x_checkpoint(args.checkpoint_path) | ||
kashif marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| t5_checkpoint = jnp.tree_util.tree_map(onp.array, t5_checkpoint) | ||
|
|
||
| gin_overrides = [ | ||
| "from __gin__ import dynamic_registration", | ||
| "from music_spectrogram_diffusion.models.diffusion import diffusion_utils", | ||
| "diffusion_utils.ClassifierFreeGuidanceConfig.eval_condition_weight = 2.0", | ||
| "diffusion_utils.DiffusionConfig.classifier_free_guidance = @diffusion_utils.ClassifierFreeGuidanceConfig()", | ||
| ] | ||
|
|
||
| gin_file = os.path.join(args.checkpoint_path, "..", "config.gin") | ||
| gin_config = inference.parse_training_gin_file(gin_file, gin_overrides) | ||
kashif marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| synth_model = inference.InferenceModel(args.checkpoint_path, gin_config) | ||
|
|
||
| scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2", variance_type="fixed_large") | ||
|
|
||
| notes_encoder = SpectrogramNotesEncoder( | ||
| max_length=synth_model.sequence_length["inputs"], | ||
| vocab_size=synth_model.model.module.config.vocab_size, | ||
| d_model=synth_model.model.module.config.emb_dim, | ||
| dropout_rate=synth_model.model.module.config.dropout_rate, | ||
| num_layers=synth_model.model.module.config.num_encoder_layers, | ||
| num_heads=synth_model.model.module.config.num_heads, | ||
| d_kv=synth_model.model.module.config.head_dim, | ||
| d_ff=synth_model.model.module.config.mlp_dim, | ||
| feed_forward_proj="gated-gelu", | ||
| ) | ||
|
|
||
| continuous_encoder = SpectrogramContEncoder( | ||
| input_dims=synth_model.audio_codec.n_dims, | ||
| targets_context_length=synth_model.sequence_length["targets_context"], | ||
| d_model=synth_model.model.module.config.emb_dim, | ||
| dropout_rate=synth_model.model.module.config.dropout_rate, | ||
| num_layers=synth_model.model.module.config.num_encoder_layers, | ||
| num_heads=synth_model.model.module.config.num_heads, | ||
| d_kv=synth_model.model.module.config.head_dim, | ||
| d_ff=synth_model.model.module.config.mlp_dim, | ||
| feed_forward_proj="gated-gelu", | ||
| ) | ||
|
|
||
| decoder = T5FilmDecoder( | ||
| input_dims=synth_model.audio_codec.n_dims, | ||
| targets_length=synth_model.sequence_length["targets_context"], | ||
| max_decoder_noise_time=synth_model.model.module.config.max_decoder_noise_time, | ||
| d_model=synth_model.model.module.config.emb_dim, | ||
| num_layers=synth_model.model.module.config.num_decoder_layers, | ||
| num_heads=synth_model.model.module.config.num_heads, | ||
| d_kv=synth_model.model.module.config.head_dim, | ||
| d_ff=synth_model.model.module.config.mlp_dim, | ||
| dropout_rate=synth_model.model.module.config.dropout_rate, | ||
| ) | ||
|
|
||
| notes_encoder = load_notes_encoder(t5_checkpoint["target"]["token_encoder"], notes_encoder) | ||
| continuous_encoder = load_continuous_encoder(t5_checkpoint["target"]["continuous_encoder"], continuous_encoder) | ||
| decoder = load_decoder(t5_checkpoint["target"]["decoder"], decoder) | ||
|
|
||
| melgan = OnnxRuntimeModel.from_pretrained("kashif/soundstream_mel_decoder") | ||
|
|
||
| pipe = SpectrogramDiffusionPipeline( | ||
| notes_encoder=notes_encoder, | ||
| continuous_encoder=continuous_encoder, | ||
| decoder=decoder, | ||
| scheduler=scheduler, | ||
| melgan=melgan, | ||
| ) | ||
| if args.save: | ||
| pipe.save_pretrained(args.output_path) | ||
|
|
||
|
|
||
| if __name__ == "__main__": | ||
| parser = argparse.ArgumentParser() | ||
|
|
||
| parser.add_argument("--output_path", default=None, type=str, required=True, help="Path to the converted model.") | ||
| parser.add_argument( | ||
| "--save", default=True, type=bool, required=False, help="Whether to save the converted model or not." | ||
| ) | ||
| parser.add_argument( | ||
| "--checkpoint_path", | ||
| default=f"{MODEL}/checkpoint_500000", | ||
| type=str, | ||
| required=False, | ||
| help="Path to the original jax model checkpoint.", | ||
| ) | ||
| args = parser.parse_args() | ||
|
|
||
| main(args) | ||
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Uh oh!
There was an error while loading. Please reload this page.