Encoding issue #157
Comments
|
Hi @TheoLechemia. |
|
I stumbled upon the same issue and it seems that every Unicode character is taking place of 2 characters and this leaks to the following lines... |
- Fixes issue in Py3 when converting text characters to byte strings, but in Py3 converts to unicode instead, because uses the Py2 specific str() function, instead of the version neutral b(). When the text contains non-ascii 2-byte unicode values this results in truncating the unicode length instead of the byte length, and thus results in incorrectly padded byte lengths and data values ending up in the wrong field/column. See #157, and also #148. - Also bump to next version.
|
That's correct. Looking further into it, it seems the old code attempted to convert to byte string before truncating and padding to the correct text size. However, it used the Py2 specific str() method instead of b(), so in Py3 it got converted to unicode before truncating, thus leading to incorrect truncating and byte lengths, and thus column underflows etc. |
|
That worked nicely and swiftly, good job 😄 |
Uh oh!
There was an error while loading. Please reload this page.
Hello,
I'm trying to create a shapefile with non ascii character ('é', 'à' etc...).
When I pass only ascii characters to the record() method, everything is fine, but since when I pass non ascii, the data are totaly mixed (data not coresponding to the columns, and some data are reported to other columns)
Here in the screen shot, the columns "nom_valide" should be only "string" and the numbers at the beginning of the column should be in the "cd_ref" column...
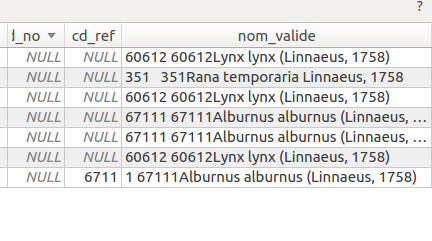
I tought I had to encode myself my data, but I saw in the code, that it's already done...
When I pass already encoded data (bytes in utf-8), everything works, but all the data columns are prefixed with a "u"... because its encoded twice...
I also saw in the doc that we can pass the encoding to the Writter class, but I think the 1.2.12 version I doesn't have this feature yet.
I'm using pyshp 1.2.12, python 3, my data come from sqlalchemy and are already in utf8
Any help ?
Thanks a lot
The text was updated successfully, but these errors were encountered: