Improved cw-2.py #571
Improved cw-2.py #571
Conversation
* Make testing functions non-blocking * Change the expression inside `assert_not_equals` so that it can prevent operator injection hacks * Provide `pass_`, `fail`, and `assert_approx_equals` * Replace hardcoded `print`s with `display`
* Build the decorator version of `describe` and `it`, so the text fixture may look like this (and the decorator itself runs the code, so it doesn't need a separate runner function): ```python @Describe('describe-text') def describe1(): @it('it-text', before=f1, after=f2) def it1(): # some test function @it('it-text') def it2(): # some test function ``` * Properly close `describe` and `it` blocks in the test output * Print the running times of `describe` and `it` blocks * Provide `before` and `after` for `describe` and `it`
* Print using `"\uXXXX"` and `"\UXXXXXXXX"` literal style for tagged messages * Print using `"&#XXXX;"` HTML escape style for simple logs
|
@kazk Would it be OK to add runner-side changes upon this, if this PR isn't going to be merged soon? |
|
@Bubbler-4 Thanks! Looks good to me so far :) |
| } | ||
| }); | ||
|
|
||
| describe('Fixed and new features', function() { |
There was a problem hiding this comment.
could be solvable by providing the source charset on the first line, which in turn requires some edits in the runner code
Do you mean adding # coding: utf-8?
There was a problem hiding this comment.
Yes. But since we're going for multiple files approach, we'll need it in each file (at least preloaded, solution, and fixture).
There was a problem hiding this comment.
If we go multiple files, can users just add them when needed?
This is currently impossible because we concatenate them and the magic comment is only valid if it's in the first or the second line.
There was a problem hiding this comment.
Since we'll want to prepend something to the code when needed (just like in your unittest fix), I'd just add it to every file I create. At least it won't break existing things (because utf-8 is a superset of ascii).
|
For the runner changes, I'm thinking about these (blatantly copied from my kumite's comment section):
So it covers both the discussion here and #558, but it'll be really breaking changes. |
|
We can't have any breaking changes for this repository. Which of those are breaking changes?
Yeah, I dislike how some languages runner do these. Also that I think moving them to |
|
Huh, the Unicode fix isn't working properly within the test environment (it was only tested in non-TDD kumite). I'll see if I can fix it properly (if nothing helps, we'd need to resort to |
|
Python 2.7 is printing |
test/runners/python_spec.js
Outdated
| languageVersion: v, | ||
| testFramework: 'cw-2', | ||
| code: 'a = 1', | ||
| fixture: 'print("u\\uac00")', |
There was a problem hiding this comment.
Did you mean fixture: 'print(u"\\uac00")',? "u vs u". Not sure if that makes any difference.
There was a problem hiding this comment.
For Python 2.7, fixing this should make the test pass.
print(u"\uac00") #=> 가
print("u\uac00") #=> u\uac00
frameworks/python/cw-2.py
Outdated
|
|
||
|
|
||
| '''Fix the dreaded Unicode Error Trap''' | ||
| def print(*args, **kwargs): |
There was a problem hiding this comment.
This print doesn't seem to work when given non-string, e.g., print(1) throws
TypeError: 'int' object is not iterable
in Python 2.7 and
TypeError: print() argument after * must be a sequence, not map
in Python 3
frameworks/python/cw-2.py
Outdated
| def _replace(c): | ||
| if ord(c) >= 128: return u'&#{};'.format(ord(c)) | ||
| return c | ||
| def _escape(s): return ''.join(_replace(c) for c in s) |
There was a problem hiding this comment.
In Python 2, the above error is from this _escape.
 kazk
left a comment
kazk
left a comment
There was a problem hiding this comment.
printneeds to behave the same way as the builtin one- The Unicode fix needs to be fixed or removed
- Maybe provide a convenience function instead of replacing
print()?
test/runners/python_spec.js
Outdated
| languageVersion: v, | ||
| testFramework: 'cw-2', | ||
| code: 'a = 1', | ||
| fixture: 'print("u\\uac00")', |
There was a problem hiding this comment.
For Python 2.7, fixing this should make the test pass.
print(u"\uac00") #=> 가
print("u\uac00") #=> u\uac00|
I'm out today, so changes won't be made until tomorrow. |
|
Don't worry, take your time. I just wanted to leave some feedback because I don't know if I have the time to review during the week. |
|
@Bubbler-4
Setting environment variable can be done by changing to run({
name: pythonCmd(opts),
args: ['-c', code],
options: {
env: Object.assign({}, process.env, {PYTHONIOENCODING: 'UTF-8'})
}
}); |
frameworks/python/cw-2.py
Outdated
| def _escape(s): return ''.join(_replace(c) for c in s) | ||
|
|
||
| def _escape(s): | ||
| if isinstance(s, six.string_types): |
There was a problem hiding this comment.
Apparently six.string_types doesn't include unicode, so replace this with six.text_type?
|
Finally solved it, without using environment variables:
|
| testFramework: 'cw-2', | ||
| code: 'a = 1', | ||
| fixture: 'print(1, "2", u"\\uac00")', | ||
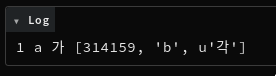
| fixture: 'test.uni_print(1, "a", u"\\uac00", [314159, "b", u"\\uac01"])', |
There was a problem hiding this comment.
For Python 2, this is printing:
1 a 가 [314159, 'b', u'각']

https://travis-ci.org/Codewars/codewars-runner-cli/jobs/340822289#L1401
There was a problem hiding this comment.
Should I remove the u flag in front of the literal? I think I'll leave it there, because str and unicode are two different things in Py2.
There was a problem hiding this comment.
Ok, I didn't realize that was intentional. So it'll be rendered like this:
There was a problem hiding this comment.
Yes, I tested the output using my kumite on CW, but I don't know how it'll be displayed on Qualified.
|
Looks good to me! I'll try to do some testing against existing contents during this week. And thanks for looking into the Unicode issue and |
|
The workaround should work just fine because, if Glad you like it 😄 |

# Conflicts: # test/runners/python_spec.js
|
@Bubbler-4 Sorry for the delay. I didn't have the time to test this last week. |
|
I found the root cause of the Unicode issue: https://bugs.python.org/issue19846 The new runner uses the official Docker image with ( Now we have |
|
When will this be employed to the main CW site (or preview site)? I miss new changes :( |
|
I haven't found anything major (looking at the number of successful Python completions) so this should be safe to merge. If we do, try not to use |
|
@Bubbler-4 |
|
I just made an example kumite, and the new framework works perfectly 👍 Just one thing is, it looks like the runner overhead has increased by ~500ms. It shouldn't be too much of a concern except for a few katas that are insanely tight on the bound, but maybe you can consider increasing the time limit to 12500ms. |
|
Thanks for trying it out. I realized that The issue with printing Unicode should be resolved as well. I've also avoided concatenation so the error message should be more clear. But I might need to revert it because I noticed some kata uses test methods in preloaded section. Yeah, the wall time (time displayed at the top) won't be the same because the time includes some extra steps. The actual test execution time (time inside test results) shouldn't be that different. I might make some adjustments later if this is a major problem, but overall the performance should be better and more stable for most of the languages. I'm not too worried because the old runner have inconsistent performance and the wall time can vary more than 500ms. |
How about prepending |
|
Yeah, concatenation is terrible for UX. I'll prepend |
|
@Bubbler-4 Python is executed like the following: Writing Files setup.py (preloaded, if given) test = Test = __import__('cw-2')
# preloadedsolution.py from setup import * # if preloaded is given
# solutionmain.py from solution import *
test = Test = __import__('cw-2')
# testsRun
Many of the affected kata can be fixed by avoiding the use of private variables ( |
|
I've added it with slight modification. I'll deploy it maybe tomorrow along with other languages that I need to fix. |
|
@Bubbler-4 |
|
I'm going to merge this so @Bubbler-4 gets some credit for it. The actual source that was derived from this will be open sourced later. |
|
Hi guys, I might have found a way to efficiently forbid the import of modules in python (I doubt it will be bullet proof, I'm not enough in the deep structure of python to know. Though, it seems at least not easy to crack). That could be a nice addition to the test framework, I believe, in the following manner:
I'd send to both of you (@Bubbler-4, @kazk) the code by MP on gitter (I'd rather like that it's not visible for now), so that you can tell me if you think it's worth of the addition. Cheers, |
This PR introduces many improvements based on the discussions at #569 and my own Kumite.
Testing Functions
assert_not_equalsso that it can prevent operator injection hackspass_,fail, andassert_approx_equalswith customizable precision (passis a Python keyword)prints withdisplayDescribe and It
describeandit, so the text fixture may look like this (and the decorator itself runs the code, so it doesn't need a separate runner function):describeanditblocks in the test outputdescribeanditblocksbeforeandafterfordescribeanditTimeout Utility
The Unicode Error Trap
"\uXXXX"and"\UXXXXXXXX"literal style for tagged messages"&#XXXX;"HTML escape style for simple logscw-2.py)