 \ No newline at end of file
+
diff --git a/_posts/2014-10-13-as-an-applied-statistician-i-find-the-frequentists-versus-bayesians-debate-completely-inconsequential.md b/_posts/2014-10-13-as-an-applied-statistician-i-find-the-frequentists-versus-bayesians-debate-completely-inconsequential.md
index 008f4f7..22e7ea0 100644
--- a/_posts/2014-10-13-as-an-applied-statistician-i-find-the-frequentists-versus-bayesians-debate-completely-inconsequential.md
+++ b/_posts/2014-10-13-as-an-applied-statistician-i-find-the-frequentists-versus-bayesians-debate-completely-inconsequential.md
@@ -35,36 +35,34 @@ In a recent New York Times [article](http://www.nytimes.com/2014/09/30/science/t
-Because the real story (or non-story) is way too boring to sell newspapers, the author resorted to a sensationalist narrative that went something like this: "Evil and/or stupid frequentists were ready to let a fisherman die; the persecuted Bayesian heroes saved him." This piece adds to the growing number of writings blaming frequentist statistics for the so-called reproducibility crisis in science. If there is something Roger, [Jeff](http://simplystatistics.org/2013/11/26/statistical-zealots/) and [I](http://simplystatistics.org/2013/08/01/the-roc-curves-of-science/) agree on is that this debate is [not constructive](http://noahpinionblog.blogspot.com/2013/01/bayesian-vs-frequentist-is-there-any.html). As [Rob Kass](http://arxiv.org/pdf/1106.2895v2.pdf) suggests it's time to move on to pragmatism. Here I follow up Jeff's recent post by sharing related thoughts brought about by two decades of practicing applied statistics and hope it helps put this unhelpful debate to rest.
+Because the real story (or non-story) is way too boring to sell newspapers, the author resorted to a sensationalist narrative that went something like this: "Evil and/or stupid frequentists were ready to let a fisherman die; the persecuted Bayesian heroes saved him." This piece adds to the growing number of writings blaming frequentist statistics for the so-called reproducibility crisis in science. If there is something Roger, [Jeff](http://simplystatistics.org/2013/11/26/statistical-zealots/) and [I](http://simplystatistics.org/2013/08/01/the-roc-curves-of-science/) agree on is that this debate is [not constructive](http://noahpinionblog.blogspot.com/2013/01/bayesian-vs-frequentist-is-there-any.html). As [Rob Kass](http://arxiv.org/pdf/1106.2895v2.pdf) suggests it's time to move on to pragmatism. Here I follow up Jeff's [recent post](http://simplystatistics.org/2014/09/30/you-think-p-values-are-bad-i-say-show-me-the-data/) by sharing related thoughts brought about by two decades of practicing applied statistics and hope it helps put this unhelpful debate to rest.
+
-
\ No newline at end of file
+
diff --git a/_posts/2014-10-13-as-an-applied-statistician-i-find-the-frequentists-versus-bayesians-debate-completely-inconsequential.md b/_posts/2014-10-13-as-an-applied-statistician-i-find-the-frequentists-versus-bayesians-debate-completely-inconsequential.md
index 008f4f7..22e7ea0 100644
--- a/_posts/2014-10-13-as-an-applied-statistician-i-find-the-frequentists-versus-bayesians-debate-completely-inconsequential.md
+++ b/_posts/2014-10-13-as-an-applied-statistician-i-find-the-frequentists-versus-bayesians-debate-completely-inconsequential.md
@@ -35,36 +35,34 @@ In a recent New York Times [article](http://www.nytimes.com/2014/09/30/science/t
-Because the real story (or non-story) is way too boring to sell newspapers, the author resorted to a sensationalist narrative that went something like this: "Evil and/or stupid frequentists were ready to let a fisherman die; the persecuted Bayesian heroes saved him." This piece adds to the growing number of writings blaming frequentist statistics for the so-called reproducibility crisis in science. If there is something Roger, [Jeff](http://simplystatistics.org/2013/11/26/statistical-zealots/) and [I](http://simplystatistics.org/2013/08/01/the-roc-curves-of-science/) agree on is that this debate is [not constructive](http://noahpinionblog.blogspot.com/2013/01/bayesian-vs-frequentist-is-there-any.html). As [Rob Kass](http://arxiv.org/pdf/1106.2895v2.pdf) suggests it's time to move on to pragmatism. Here I follow up Jeff's recent post by sharing related thoughts brought about by two decades of practicing applied statistics and hope it helps put this unhelpful debate to rest.
+Because the real story (or non-story) is way too boring to sell newspapers, the author resorted to a sensationalist narrative that went something like this: "Evil and/or stupid frequentists were ready to let a fisherman die; the persecuted Bayesian heroes saved him." This piece adds to the growing number of writings blaming frequentist statistics for the so-called reproducibility crisis in science. If there is something Roger, [Jeff](http://simplystatistics.org/2013/11/26/statistical-zealots/) and [I](http://simplystatistics.org/2013/08/01/the-roc-curves-of-science/) agree on is that this debate is [not constructive](http://noahpinionblog.blogspot.com/2013/01/bayesian-vs-frequentist-is-there-any.html). As [Rob Kass](http://arxiv.org/pdf/1106.2895v2.pdf) suggests it's time to move on to pragmatism. Here I follow up Jeff's [recent post](http://simplystatistics.org/2014/09/30/you-think-p-values-are-bad-i-say-show-me-the-data/) by sharing related thoughts brought about by two decades of practicing applied statistics and hope it helps put this unhelpful debate to rest.
+
-Applied statisticians help answer questions with data. How should I design a roulette so my casino makes $? Does this fertilizer increase crop yield? Does streptomycin cure pulmonary tuberculosis? Does smoking cause cancer? What movie would would this user enjoy? Which baseball player should the Red Sox give a contract to? Should this patient receive chemotherapy? Our involvement typically means analyzing data and designing experiments. To do this we use a variety of techniques that have been successfully applied in the past and that we have mathematically shown to have desirable properties. Some of these tools are frequentist, some of them are Bayesian, some could be argued to be both, and some don't even use probability. The Casino will do just fine with frequentist statistics, while the baseball team might want to apply a Bayesian approach to avoid overpaying for players that have simply been lucky. -
-- It is also important to remember that good applied statisticians also *think*. They don't apply techniques blindly or religiously. If applied statisticians, regardless of their philosophical bent, are asked if the sun just exploded, they would not design an experiment as the one depicted in this popular XKCD cartoon. -
-
+
+ It is also important to remember that good applied statisticians also **think**. They don't apply techniques blindly or religiously. If applied statisticians, regardless of their philosophical bent, are asked if the sun just exploded, they would not design an experiment as the one depicted in this popular XKCD cartoon.
+
+
+
 -
-
+ + Only someone that does not know how to think like a statistician would act like the frequentists in the cartoon. Unfortunately we do have such people analyzing data. But their choice of technique is not the problem, it's their lack of critical thinking. However, even the most frequentist-appearing applied statistician understands Bayes rule and will adapt the Bayesian approach when appropriate. In the above XCKD example, any respectful applied statistician would not even bother examining the data (the dice roll), because they would assign a probability of 0 to the sun exploding (the empirical prior based on the fact that they are alive). However, superficial propositions arguing for wider adoption of Bayesian methods fail to realize that using these techniques in an actual data analysis project is very different from simply thinking like a Bayesian. To do this we have to represent our intuition or prior knowledge (or whatever you want to call it) with mathematical formulae. When theoretical Bayesians pick these priors, they mainly have mathematical/computational considerations in mind. In practice we can't afford this luxury: a bad prior will render the analysis useless regardless of its convenient mathematically properties. -
-- Despite these challenges, applied statisticians regularly use Bayesian techniques successfully. In one of the fields I work in, Genomics, empirical Bayes techniques are widely used. In this popular application of empirical Bayes we use data from all genes to improve the precision of estimates obtained for specific genes. However, the most widely used output of the software implementation is not a posterior probability. Instead, an empirical Bayes technique is used to improve the estimate of the standard error used in a good ol' fashioned t-test. This idea has changed the way thousands of Biologists search for differential expressed genes and is, in my opinion, one of the most important contributions of Statistics to Genomics. Is this approach frequentist? Bayesian? To this applied statistician it doesn't really matter. -
-
- For those arguing that simply switching to a Bayesian philosophy will improve the current state of affairs, let's consider the smoking and cancer example. Today there is wide agreement that smoking causes lung cancer. Without a clear deductive biochemical/physiological argument and without
the possibility of a randomized trial, this connection was established with a series of observational studies. Most, if not all, of the associated data analyses were based on frequentist techniques. None of the reported confidence intervals on their own established the consensus. Instead, as usually happens in science, a long series of studies supporting this conclusion were needed. How exactly would this have been different with a strictly Bayesian approach? Would a single paper been enough? Would using priors helped given the "expert knowledge" at the time (see below)?
-
+ Despite these challenges, applied statisticians regularly use Bayesian techniques successfully. In one of the fields I work in, Genomics, empirical Bayes techniques are widely used. In [this](http://www.ncbi.nlm.nih.gov/pubmed/16646809) popular application of empirical Bayes we use data from all genes to improve the precision of estimates obtained for specific genes. However, the most widely used output of the software implementation is not a posterior probability. Instead, an empirical Bayes technique is used to improve the estimate of the standard error used in a good ol' fashioned t-test. This idea has changed the way thousands of Biologists search for differential expressed genes and is, in my opinion, one of the most important contributions of Statistics to Genomics. Is this approach frequentist? Bayesian? To this applied statistician it doesn't really matter.
+
+
+
+ For those arguing that simply switching to a Bayesian philosophy will improve the current state of affairs, let's consider the smoking and cancer example. Today there is wide agreement that smoking causes lung cancer. Without a clear deductive biochemical/physiological argument and without the possibility of a randomized trial, this connection was established with a series of observational studies. Most, if not all, of the associated data analyses were based on frequentist techniques. None of the reported confidence intervals on their own established the consensus. Instead, as usually happens in science, a long series of studies supporting this conclusion were needed. How exactly would this have been different with a strictly Bayesian approach? Would a single paper been enough? Would using priors helped given the "expert knowledge" at the time (see below)?
+
+
+
 -
-
+ And how would the Bayesian analysis performed by tabacco companies shape the debate? Ultimately, I think applied statisticians would have made an equally convincing case against smoking with Bayesian posteriors as opposed to frequentist confidence intervals. Going forward I hope applied statisticians continue to be free to use whatever techniques they see fit and that critical thinking about data continues to be what distinguishes us. Imposing Bayesian or frequentists philosophy on us would be a disaster. -
\ No newline at end of file diff --git a/_posts/2014-11-04-538-election-forecasts-made-simple.md b/_posts/2014-11-04-538-election-forecasts-made-simple.md index 323ddff..c7a2c4f 100644 --- a/_posts/2014-11-04-538-election-forecasts-made-simple.md +++ b/_posts/2014-11-04-538-election-forecasts-made-simple.md @@ -21,10 +21,10 @@ categories: --- Nate Silver does a [great job](http://fivethirtyeight.com/features/how-the-fivethirtyeight-senate-forecast-model-works/) of explaining his forecast model to laypeople. However, as a statistician I've always wanted to know more details. After preparing a "predict the midterm elections" homework for my [data science class](http://cs109.github.io/2014) I have a better idea of what is going on. -[Here](http://rafalab.jhsph.edu/simplystats/midterm2012.html) is my best attempt at explaining the ideas of 538 using formulas and data. And [here](http://rafalab.jhsph.edu/simplystats/midterm2012.Rmd) is the R markdown. +[Here](http://simplystatistics.org/html/midterm2012.html) is my best attempt at explaining the ideas of 538 using formulas and data. ~~And [here](http://rafalab.jhsph.edu/simplystats/midterm2012.Rmd) is the R markdown.~~ - \ No newline at end of file + diff --git a/_posts/2016-10-26-datasets-new-server-rooms.md b/_posts/2016-10-26-datasets-new-server-rooms.md new file mode 100644 index 0000000..dc1b181 --- /dev/null +++ b/_posts/2016-10-26-datasets-new-server-rooms.md @@ -0,0 +1,28 @@ +--- +title: Are Datasets the New Server Rooms? +author: roger +layout: post +comments: false +--- + +Josh Nussbaum has an [interesting post](https://medium.com/@josh_nussbaum/data-sets-are-the-new-server-rooms-40fdb5aed6b0?_hsenc=p2ANqtz-8IHAReMPP2JjyYs6TqyMYCnjUapQdLQFEaQOjNX9BfUhZV2nzXWwy2NHJHrCs-VN67GxT4djKCUWq8tkhTyiQkb965bg&_hsmi=36470868#.wz8f23tak) over at Medium about whether massive datasets are the new server rooms of tech business. + +The analogy comes from the "old days" where in order to start an Internet business, you had to buy racks and servers, rent server space, buy network bandwidth, license expensive server software, backups, and on and on. In order to do all that up front, it required a substantial amount of capital just to get off the ground. As inconvenient as this might have been, it provided an immediate barrier to entry for any other competitors who weren't able to raise similar capital. + +Of course, + +> ...the emergence of open source software and cloud computing completely eviscerated the costs and barriers to starting a company, leading to deflationary economics where one or two people could start their company without the large upfront costs that were historically the hallmark of the VC industry. + +So if startups don't have huge capital costs in the beginning, what costs *do* they have? Well, for many new companies that rely on machine learning, they need to collect data. + +> As a startup collects the data necessary to feed their ML algorithms, the value the product/service provides improves, allowing them to access more customers/users that provide more data and so on and so forth. + +Collecting huge datasets ultimately costs money. The sooner a startup can raise money to get that data, the sooner they can defend themselves from competitors who may not yet have collected the huge datasets for training their algorithms. + +I'm not sure the analogy between datasets and server rooms quite works. Even back when you had to pay a lot of up front costs to setup servers and racks, a lot of that technology was already a commodity, and anyone could have access to it for a price. + +I see massive datasets used to train machine learning algorithms as more like the new proprietary software. The startups of yore spent a lot of time writing custom software for what we might now consider mundane tasks. This was a time-consuming activity but the software that was developed had value and was a differentiator for the company. Today, many companies write complex machine learning algorithms, but those algorithms and their implmentations are quickly becoming commodities. So the only thing that separates one company from another is the amount and quality of data that they have to train those algorithms. + +Going forward, it will be interesting see what these companies will do with those massive datasets once they no longer need them. Will they "open source" them and make them available to everyone? Could there be an open data movement analogous to the open source movement? + +For the most part, I doubt it. While I think many today would perhaps sympathize with the sentiment that [software shouldn't have owners](https://www.gnu.org/gnu/manifesto.en.html), those same people I think would argue vociferously that data most certainly do have owners. I'm not sure how I'd feel if Facebook made all their data available to anyone. That said, many datasets are made available by various businesses, and as these datasets grow in number and in usefulness, we may see a day where the collection of data is not a key barrier to entry, and that you can train your machine learning algorithm on whatever is out there. \ No newline at end of file diff --git a/_posts/2016-10-28-nssd-episode-25.md b/_posts/2016-10-28-nssd-episode-25.md new file mode 100644 index 0000000..467b3d2 --- /dev/null +++ b/_posts/2016-10-28-nssd-episode-25.md @@ -0,0 +1,35 @@ +--- +author: roger +layout: post +title: Not So Standard Deviations Episode 25 - How Exactly Do You Pronounce SQL? +--- + +Hilary and I go through the overflowing mailbag to respond to listener questions! Topics include causal inference in trend modeling, regression model selection, using SQL, and data science certification. + +If you have questions you’d like us to answer, you can send them to +nssdeviations @ gmail.com or tweet us at [@NSSDeviations](https://twitter.com/nssdeviations). + +Show notes: + +* [Professor Kobre's Lightscoop Standard Version Bounce Flash Device](https://www.amazon.com/gp/product/B0017LNHY2/) + +* [Speechpad](https://www.speechpad.com) + +* [Speaking American by Josh Katz](https://www.amazon.com/gp/product/0544703391/) + +* [Data Sets Are The New Server Rooms](https://medium.com/@josh_nussbaum/data-sets-are-the-new-server-rooms-40fdb5aed6b0?_hsenc=p2ANqtz-8IHAReMPP2JjyYs6TqyMYCnjUapQdLQFEaQOjNX9BfUhZV2nzXWwy2NHJHrCs-VN67GxT4djKCUWq8tkhTyiQkb965bg&_hsmi=36470868#.wybl0l3p7) + +* [Are Datasets the New Server Rooms?](http://simplystatistics.org/2016/10/26/datasets-new-server-rooms/) + +* Subscribe to the podcast on [iTunes](https://itunes.apple.com/us/podcast/not-so-standard-deviations/id1040614570) or [Google Play](https://play.google.com/music/listen?u=0#/ps/Izfnbx6tlruojkfrvhjfdj3nmna). And please [leave us a review on iTunes](https://itunes.apple.com/us/podcast/not-so-standard-deviations/id1040614570). + +* Support us through our [Patreon page](https://www.patreon.com/NSSDeviations?ty=h). + +* Get the [Not So Standard Deviations book](https://leanpub.com/conversationsondatascience/). + + +[Download the audio for this episode](https://soundcloud.com/nssd-podcast/episode-25-how-exactly-do-you-pronounce-sql) + +Listen here: + + \ No newline at end of file diff --git a/_posts/2016-11-08-chromebook-part2.md b/_posts/2016-11-08-chromebook-part2.md new file mode 100644 index 0000000..545d752 --- /dev/null +++ b/_posts/2016-11-08-chromebook-part2.md @@ -0,0 +1,24 @@ +--- +title: Data scientist on a chromebook take two +author: jeff +layout: post +comments: true +--- + +My friend Fernando showed me his collection of [old Apple dongles](https://twitter.com/jtleek/status/795749713966497793) that no longer work with the latest generation of Apple devices. This coupled with the announcement of the Macbook pro that promises way more dongles and mostly the same computing, had me freaking out about my computing platform for the future. I've been using cloudy tools for more and more of what I do and so it had me wondering if it was time to go back and try my [Chromebook experiment](http://simplystatistics.org/2012/01/09/a-statistician-and-apple-fanboy-buys-a-chromebook-and/) again. Basically the question is whether I can do everything I need to do comfortably on a Chromebook. + +So to execute the experience I got a brand new [ASUS chromebook flip](https://www.asus.com/us/Notebooks/ASUS_Chromebook_Flip_C100PA/) and the connector I need to plug it into hdmi monitors (there is no escaping at least one dongle I guess :(). Here is what that badboy looks like in my home office with Apple superfanboy Roger on the screen. + + + + +In terms of software there have been some major improvements since I last tried this experiment out. Some of these I talk about in my book [How to be a modern scientist](https://leanpub.com/modernscientist). As of this writing this is my current setup: + +* Music on [Google Play](https://play.google.com) +* Latex on [Overleaf](https://www.overleaf.com) +* Blog/website/code on [Github](https://github.com/) +* R programming on an [Amazon AMI with Rstudio loaded](http://www.louisaslett.com/RStudio_AMI/) although [I hear](https://twitter.com/earino/status/795750908457984000) there may be other options that are good there that I should try. +* Email/Calendar/Presentations/Spreadsheets/Docs with [Google](https://www.google.com/) products +* Twitter with [Tweetdeck](https://tweetdeck.twitter.com/) + +That handles the vast majority of my workload so far (its only been a day :)). But I would welcome suggestions and I'll report back when either I give up or if things are still going strong in a little while.... diff --git a/_posts/2016-11-09-not-all-forecasters-got-it-wrong.md b/_posts/2016-11-09-not-all-forecasters-got-it-wrong.md new file mode 100644 index 0000000..fa13785 --- /dev/null +++ b/_posts/2016-11-09-not-all-forecasters-got-it-wrong.md @@ -0,0 +1,76 @@ +--- +title: 'Not all forecasters got it wrong: Nate Silver does it again (again)' +date: 2016-11-09 +author: rafa +layout: post +comments: true +--- + +Four years ago we +[posted](http://simplystatistics.org/2012/11/07/nate-silver-does-it-again-will-pundits-finally-accept/) +on Nate Silver's, and other forecasters', triumph over pundits. In +contrast, after yesterday's presidential election, results contradicted +most polls and data-driven forecasters, several news articles came out +wondering how this happened. It is important to point +out that not all forecasters got it wrong. Statistically +speaking, Nate Silver, once again, got it right. + +To show this, below I include a plot showing the expected margin of +victory for Clinton versus the actual results for the most competitive states provided by 538. It includes the uncertainty bands provided by 538 in +[this site](http://projects.fivethirtyeight.com/2016-election-forecast/) +(I eyeballed the band sizes to make the plot in R, so they are not +exactly like 538's). + +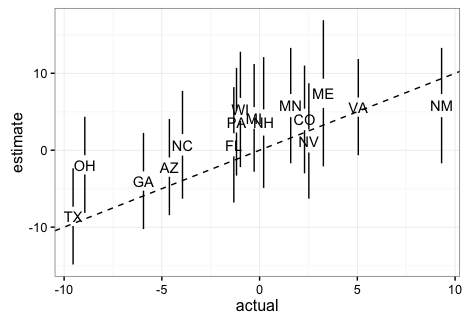 + +Note that if these are 95% confidence/credible intervals, 538 got 1 +wrong. This is exactly what we expect since 15/16 is about +95%. Furthermore, judging by the plot [here](http://projects.fivethirtyeight.com/2016-election-forecast/), 538 estimated the popular vote margin to be 3.6% +with a confidence/credible interval of about 5%. +This too was an accurate +prediction since Clinton is going to win the popular vote by +about 1% ~~0.5%~~ (note this final result is in the margin of error of +several traditional polls as well). Finally, when other forecasters were +giving Trump between 14% and 0.1% chances of winning, 538 gave +him about a +30% chance which is slightly more than what a team has when down 3-2 +in the World Series. In contrast, in 2012 538 gave Romney only a 9% +chance of winning. Also, remember, if in ten election cycles you +call it for someone with a 70% chance, you should get it wrong 3 +times. If you get it right every time then your 70% statement was wrong. + +So how did 538 outperform all other forecasters? First, as far as I +can tell they model the possibility of an overall bias, modeled as a +random effect, that affects +every state. This bias can be introduced by systematic +lying to pollsters or under sampling some group. Note that this bias +can't be estimated from data from +one election cycle but it's variability can be estimated from +historical data. 538 appear +to estimate the standard error of this term to be +about 2%. More details on this are included [here](http://simplystatistics.org/html/midterm2012.html). In 2016 we saw this bias and you can see it in +the plot above (more points are above the line than below). The +confidence bands account for this source of variabilty and furthermore +their simulations account for the strong correlation you will see +across states: the chance of seeing an upset in Pennsylvania, Wisconsin, +and Michigan is **not** the product of an upset in each. In +fact it's much higher. Another advantage 538 had is that they somehow +were able to predict a systematic, not random, bias against +Trump. You can see this by +comparing their adjusted data to the raw data (the adjustment favored +Trump about 1.5 on average). We can clearly see this when comparing the 538 +estimates to The Upshots': + + +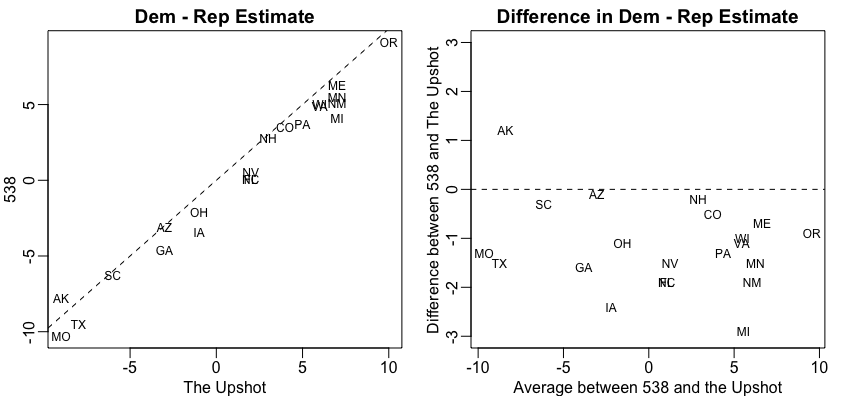 + +The fact that 538 did so much better than other forecasters should +remind us how hard it is to do data analysis in real life. Knowing +math, statistics and programming is not enough. It requires experience +and a deep understanding of the nuances related to the specific +problem at hand. Nate Silver and the 538 team seem to understand this +more than others. + +Update: Jason Merkin points out (via Twitter) that 538 provides 80% credible +intervals. + diff --git a/_posts/2016-11-11-im-not-moving-to-canada.md b/_posts/2016-11-11-im-not-moving-to-canada.md new file mode 100644 index 0000000..e447dbb --- /dev/null +++ b/_posts/2016-11-11-im-not-moving-to-canada.md @@ -0,0 +1,40 @@ +--- +title: 'Open letter to my lab: I am not "moving to Canada"' +date: 2016-11-11 +author: rafa +layout: post +comments: true +--- + +Dear Lab Members, + +I know that the results of Tuesday's election have many of you +concerned about your future. You are not alone. I am concerned +about my future as well. But I want you to know that I have no plans +of going anywhere and I intend to dedicate as much time to our +projects as I always have. Meeting, discussing ideas and putting them +into practice with you is, by far, the best part of my job. + +We are all concerned that if certain campaign promises are kept many +of our fellow citizens may need our help. If this happens, then we +will pause to do whatever we can to help. But I am currently +cautiously optimistic that we will be able to continue focusing on +helping society in the best way we know how: by doing scientific +research. + +This week Dr. Francis Collins assured us that there is strong +bipartisan support for scientific research. As an example consider +[this op-ed](http://www.nytimes.com/2015/04/22/opinion/double-the-nih-budget.html?_r=0) +in which Newt Gingrich advocates for doubling the NIH budget. There +also seems to be wide consensus in this country that scientific +research is highly beneficial to society and an understanding that to +do the best research we need the best of the best no matter their +gender, race, religion or country of origin. Nothing good comes from +creative, intelligent, dedicated people leaving science. + +I know there is much uncertainty but, as of now, there is nothing stopping us +from continuing to work hard. My plan is to do just that and I hope +you join me. + + + diff --git a/_posts/2016-11-17-leekgroup-colors.md b/_posts/2016-11-17-leekgroup-colors.md new file mode 100644 index 0000000..178683b --- /dev/null +++ b/_posts/2016-11-17-leekgroup-colors.md @@ -0,0 +1,19 @@ +--- +title: Help choose the Leek group color palette +author: jeff +layout: post +comments: true +--- + +My research group just recently finish a paper where several different teams within the group worked on different analyses. If you are interested the paper describes the [recount resource](http://biorxiv.org/content/early/2016/08/08/068478) which includes processed versions of thousands of human RNA-seq data sets. + +As part of this project each group had to contribute some plots to the paper. One thing that I noticed is that each person used their own color palette and theme when building the plots. When we wrote the paper this made it a little harder for the figures to all fit together - especially when different group members worked on a single panel of a multi-panel plot. + +So I started thinking about setting up a Leek group theme for both base R and ggplot2 graphics. One of the first problems was that every group member had their own opinion about what the best color palette would be. So we are running a little competition to determine what the official Leek group color palette for plots will be in the future. + +As part of that process, one of my awesome postdocs, Shannon Ellis, decided to collect some data on how people perceive different color palettes. The survey is here: + +https://docs.google.com/forms/d/e/1FAIpQLSfHMXVsl7pxYGarGowJpwgDSf9lA2DfWJjjEON1fhuCh6KkRg/viewform?c=0&w=1 + +If you have a few minutes and have an opinion about colors (I know you do!) please consider participating in our little poll and helping to determine the future of Leek group plots! + diff --git a/_posts/2016-11-30-nssd-episode-27.md b/_posts/2016-11-30-nssd-episode-27.md new file mode 100644 index 0000000..c09d14f --- /dev/null +++ b/_posts/2016-11-30-nssd-episode-27.md @@ -0,0 +1,41 @@ +--- +author: roger +layout: post +title: Not So Standard Deviations Episode 27 - Special Guest Amelia McNamara +--- + +I had the pleasure of sitting down with Amelia McNamara, Visiting Assistant Professor of Statistical and Data Sciences at Smith College, to talk about data science, data journalism, visualization, the problems with R, and adult coloring books. + +If you have questions you’d like Hilary and me to answer, you can send them to nssdeviations @ gmail.com or tweet us at [@NSSDeviations](https://twitter.com/nssdeviations). + +Show notes: + +* [Amelia McNamara’s web site](http://www.science.smith.edu/~amcnamara/index.html) + +* [Mark Hansen](http://datascience.columbia.edu/mark-hansen) + +* [Listening Post](https://www.youtube.com/watch?v=dD36IajCz6A) + +* [Moveable Type](http://www.nytimes.com/video/arts/1194817116105/moveable-type.html) + +* [Alan Kay](https://en.wikipedia.org/wiki/Alan_Kay) + +* [HARC (Human Advancement Research Community)](https://harc.ycr.org/) + +* [VPRI (Viewpoints Research Institute)](http://www.vpri.org/index.html) + +* [Interactive essays](https://www.youtube.com/watch?v=hps9r7JZQP8) + +* [Golden Ratio Coloring Book](https://rafaelaraujoart.com/products/golden-ratio-coloring-book) + +* Subscribe to the podcast on [iTunes](https://itunes.apple.com/us/podcast/not-so-standard-deviations/id1040614570) or [Google Play](https://play.google.com/music/listen?u=0#/ps/Izfnbx6tlruojkfrvhjfdj3nmna). And please [leave us a review on iTunes](https://itunes.apple.com/us/podcast/not-so-standard-deviations/id1040614570). + +* Support us through our [Patreon page](https://www.patreon.com/NSSDeviations?ty=h). + +* Get the [Not So Standard Deviations book](https://leanpub.com/conversationsondatascience/). + + +[Download the audio for this episode](https://soundcloud.com/nssd-podcast/episode-27-special-guest-amelia-mcnamara) + +Listen here: + diff --git a/_posts/2016-12-09-pisa-us-math.md b/_posts/2016-12-09-pisa-us-math.md new file mode 100644 index 0000000..95aa968 --- /dev/null +++ b/_posts/2016-12-09-pisa-us-math.md @@ -0,0 +1,77 @@ +--- +title: 'What is going on with math education in the US?' +date: 2016-12-09 +author: rafa +layout: post +comments: true +--- + +When colleagues with young children seeking information about schools +ask me if I like the Massachusetts public school my +children attend, my answer is always the same: "it's great...except for +math". The fact is that in our household we supplement our kids' math +education with significant extra curricular work in order to ensure +that they receive a math education comparable to what we received as +children in the public system. + +The latest results from the Program for International Student +Assessment (PISA) +[results](http://www.businessinsider.com/pisa-worldwide-ranking-of-math-science-reading-skills-2016-12) +show that there is a general problem with math education in the +US. Were it a country, Massachusetts would have been in second place +in reading, sixth in science, but 20th in math, only ten points above +the OECD average of 490. The US as a whole did not fair nearly as well +as MA, and the same discrepancy between math and the other two +subjects was present. In fact, among the top 30 performing +countries ranked by their average of science and reading scores, the +US has, by far, the largest discrepancy between math and +the other two subjects tested by PISA. The difference of 27 was +substantially greater than the second largest difference, +which came from Finland at 17. Massachusetts had a difference of 28. + + +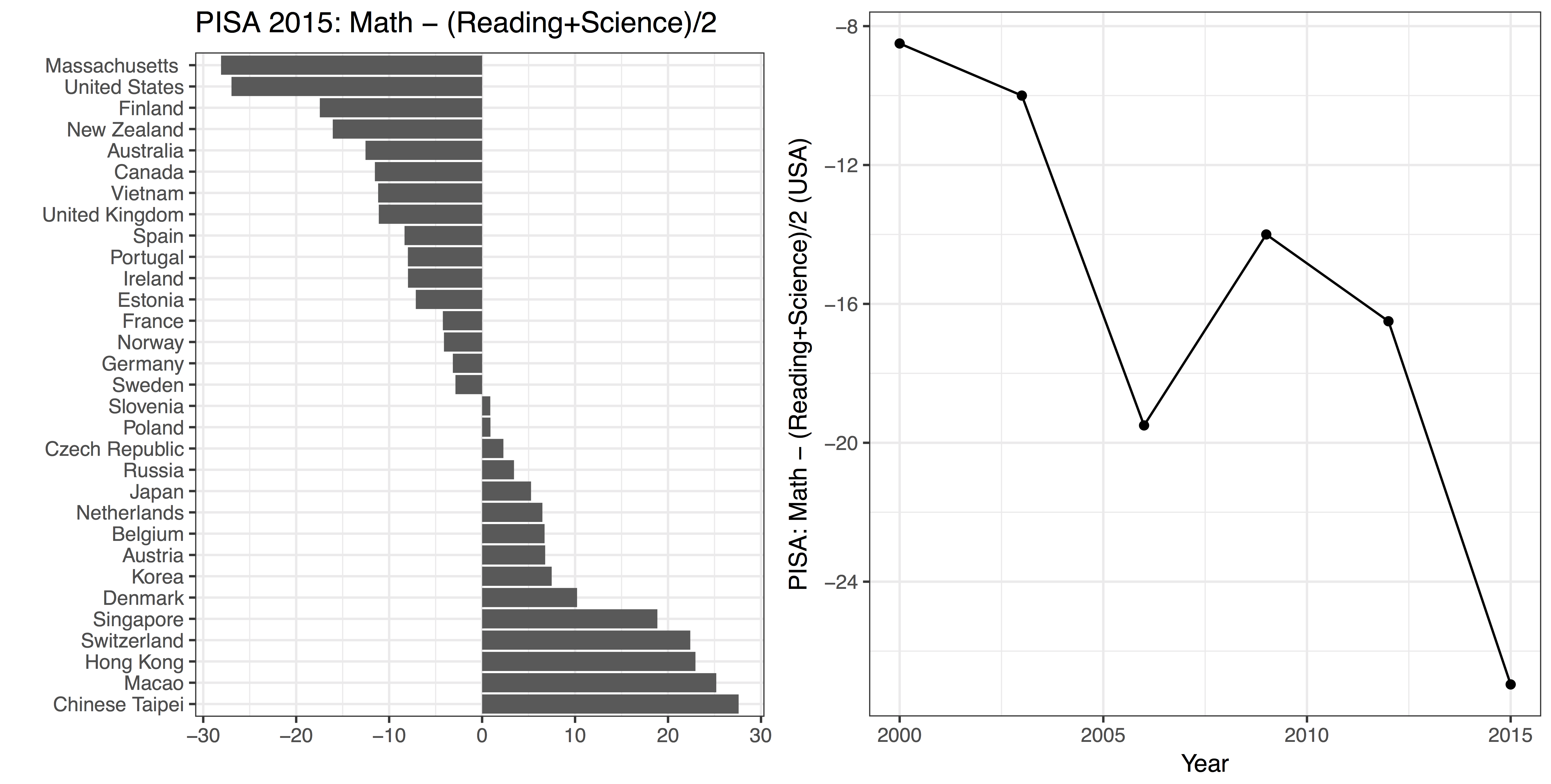 + + +If we look at the trend of this difference since PISA was started 16 +years ago, we see a disturbing progression. While science and reading +have +[remained stable, math has declined](http://www.artofteachingscience.org/wp-content/uploads/2013/12/Screen-Shot-2013-12-17-at-9.28.38-PM.png). In +2000 the difference between the results in math and the other subjects +was only 8.5. Furthermore, +the US is not performing exceptionally well in any subject: + +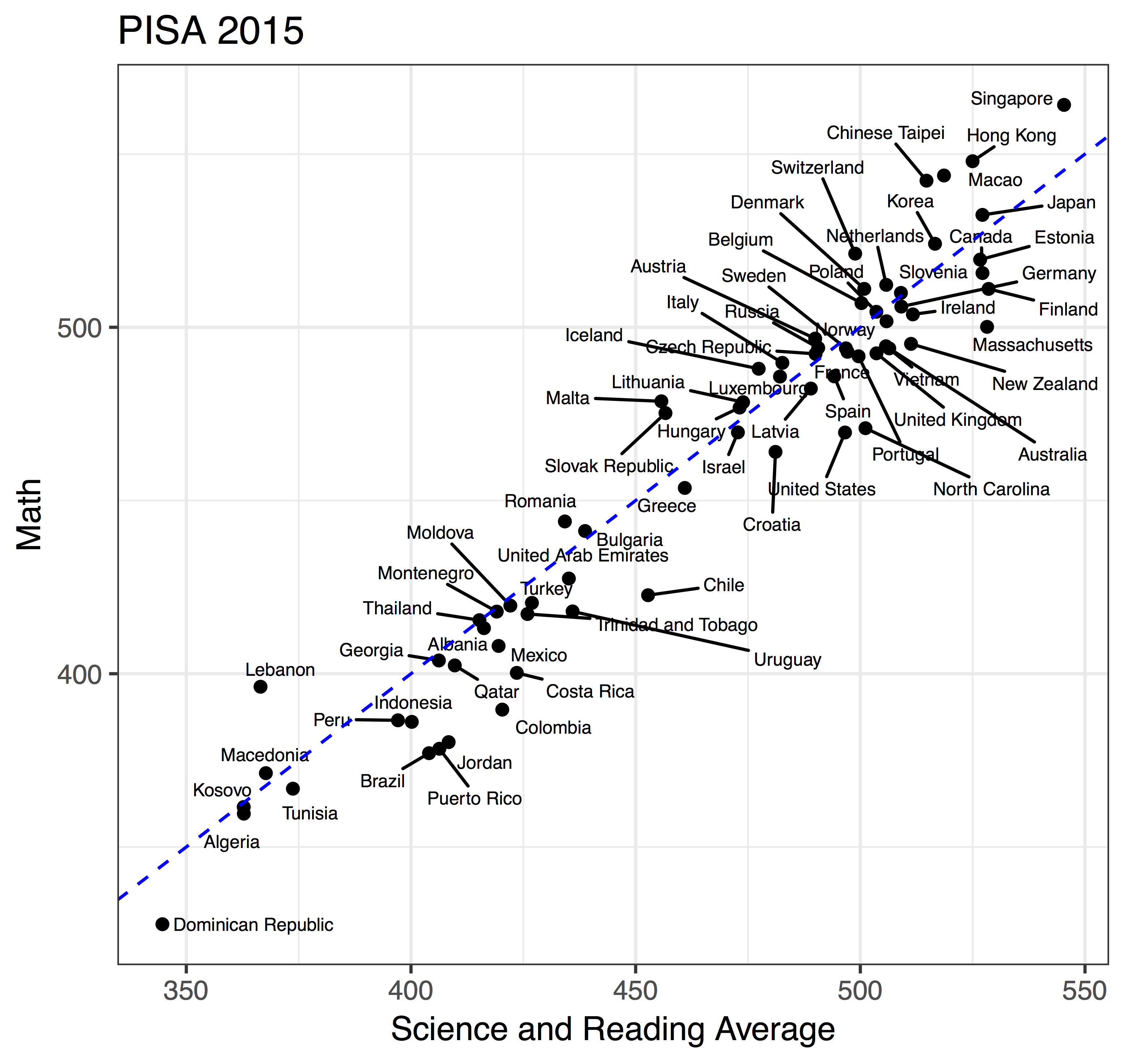 + +So what is going on? I'd love to read theories in the comment +section. From my experience comparing my kids' public schools now +with those that I attended, I have one theory of my own. When I was a +kid there was a math textbook. Even when a teacher was bad, it +provided structure and an organized alternative for learning on your +own. Today this approach is seen as being "algorithmic" and has fallen +out of favor. "Project based learning" coupled with group activities have +become popular replacements. + +Project based learning is great in principle. But, speaking from +experience, I can say it is very hard to come up with good projects, +even for highly trained mathematical minds. And it is certainly much +more time consuming for the instructor than following a +textbook. Teachers don't have more time now than they did 30 years ago +so it is no surprise that this new more open approach leads to +improvisation and mediocre lessons. A recent example of a pointless +math project involved 5th graders picking a number and preparing a +colorful poster showing "interesting" facts about this number. To +make things worse in terms of math skills, students are often rewarded +for effort, while correctness is secondary and often disregarded. + +Regardless of the reason for the decline, given the trends +we are seeing, we need to rethink the approach to math education. Math +education may have had its problems in the past, but recent evidence +suggests that the reforms of the past few decades seem to have +only worsened the situation. + +Note: To make these plots I download and read-in the data into R as described [here](https://www.r-bloggers.com/pisa-2015-how-to-readprocessplot-the-data-with-r/). + + + + diff --git a/_posts/2016-12-15-nssd-episode-28.md b/_posts/2016-12-15-nssd-episode-28.md new file mode 100644 index 0000000..6769968 --- /dev/null +++ b/_posts/2016-12-15-nssd-episode-28.md @@ -0,0 +1,24 @@ +--- +author: roger +layout: post +title: Not So Standard Deviations Episode 28 - Writing is a lot Harder than Just Talking +--- + +Hilary and I talk about building data science products that provide a good user experience while adhering to some kind of ground truth, whether it’s in medicine, education, news, or elsewhere. Also Gilmore Girls. + +If you have questions you’d like Hilary and me to answer, you can send them to nssdeviations @ gmail.com or tweet us at [@NSSDeviations](https://twitter.com/nssdeviations). + +Show notes: + +* [Hill’s criteria for causation](https://en.wikipedia.org/wiki/Bradford_Hill_criteria) +* [O’Reilly Bots Podcast](https://www.oreilly.com/topics/oreilly-bots-podcast) +* [NHTSA’s Federal Automated Vehicles Policy](http://www.nhtsa.gov/nhtsa/av/index.html) +* Subscribe to the podcast on [iTunes](https://itunes.apple.com/us/podcast/not-so-standard-deviations/id1040614570) or [Google Play](https://play.google.com/music/listen?u=0#/ps/Izfnbx6tlruojkfrvhjfdj3nmna). And please [leave us a review on iTunes](https://itunes.apple.com/us/podcast/not-so-standard-deviations/id1040614570). +* Support us through our [Patreon page](https://www.patreon.com/NSSDeviations?ty=h). +* Get the [Not So Standard Deviations book](https://leanpub.com/conversationsondatascience/). + + +[Download the audio for this episode](https://soundcloud.com/nssd-podcast/episode-28-writing-is-a-lot-harder-than-just-talking) + +Listen here: + \ No newline at end of file diff --git a/_posts/2016-12-16-the-four-eras-of-data.md b/_posts/2016-12-16-the-four-eras-of-data.md new file mode 100644 index 0000000..3ad9fcc --- /dev/null +++ b/_posts/2016-12-16-the-four-eras-of-data.md @@ -0,0 +1,37 @@ +--- +title: The four eras of data +author: jeff +layout: post +comments: true +--- + +I'm teaching [a class in data science](http://jtleek.com/advdatasci16/) for our masters and PhD students here at Hopkins. I've been teaching a variation on this class since 2011 and over time I've introduced a number of new components to the class: high-dimensional data methods (2011), data manipulation and cleaning (2012), real, possibly not doable data analyses (2012,2013), peer reviews (2014), building [swirl tutorials](http://swirlstats.com/) for data analysis techniques (2015), and this year building data analytic web apps/R packages. + +I'm the least efficient teacher in the world, probably because I'm very self conscious about my teaching. So I always feel like I have to completely re-do my lecture materials every year I teach the class (I know, I know I'm a dummy). This year I was reviewing my notes on high-dimensional data and I was looking at this breakdown of the three eras of statistics from Brad Efron's [book](http://statweb.stanford.edu/~ckirby/brad/other/2010LSIexcerpt.pdf): + +> 1. The age of Quetelet and his successors, in which huge census-level data +sets were brought to bear on simple but important questions: Are there +more male than female births? Is the rate of insanity rising? +2. The classical period of Pearson, Fisher, Neyman, Hotelling, and their +successors, intellectual giants who developed a theory of optimal inference +capable of wringing every drop of information out of a scientific +experiment. The questions dealt with still tended to be simple — Is treatment +A better than treatment B? — but the new methods were suited to +the kinds of small data sets individual scientists might collect. +3. The era of scientific mass production, in which new technologies typi- +fied by the microarray allow a single team of scientists to produce data +sets of a size Quetelet would envy. But now the flood of data is accompanied +by a deluge of questions, perhaps thousands of estimates or +hypothesis tests that the statistician is charged with answering together; +not at all what the classical masters had in mind. + +While I think this is a useful breakdown, I realized I think about it in a slightly different way as a statistician. My breakdown goes more like this: + +1. __The era of not much data__ This is everything prior to about 1995 in my field. The era when we could only collect a few measurements at a time. The whole point of statistics was to try to optimaly squeeze information out of a small number of samples - so you see methods like maximum likelihood and minimum variance unbiased estimators being developed. +2. __The era of lots of measurements on a few samples__ This one hit hard in biology with the development of the microarray and the ability to measure thousands of genes simultaneously. This is the same statistical problem as in the previous era but with a lot more noise added. Here you see the development of methods for multiple testing and regularized regression to separate signals from piles of noise. +3. __The era of a few measurements on lots of samples__ This era is overlapping to some extent with the previous one. Large scale collections of data from EMRs and Medicare are examples where you have a huge number of people (samples) but a relatively modest number of variables measured. Here there is a big focus on statistical methods for knowing how to model different parts of the data with hierarchical models and separating signals of varying strength with model calibration. +4. __The era of all the data on everything.__ This is an era that currently we as civilians don't get to participate in. But Facebook, Google, Amazon, the NSA and other organizations have thousands or millions of measurements on hundreds of millions of people. Other than just sheer computing I'm speculating that a lot of the problem is in segmentation (like in era 3) coupled with avoiding crazy overfitting (like in era 2). + +I've focused here on the implications of these eras from a statistical modeling perspective, but as we discussed in my class, era 4 coupled with advances in machine learning methods mean that there are social, economic, and behaviorial implications of these eras as well. + + diff --git a/_posts/2016-12-20-noncomprehensive-list-of-awesome.md b/_posts/2016-12-20-noncomprehensive-list-of-awesome.md new file mode 100644 index 0000000..c158b3f --- /dev/null +++ b/_posts/2016-12-20-noncomprehensive-list-of-awesome.md @@ -0,0 +1,50 @@ +--- +title: A non-comprehensive list of awesome things other people did in 2016 +author: jeff +layout: post +comments: true +--- + +_Editor's note: For the last few years I have made a list of awesome things that other people did ([2015](http://simplystatistics.org/2015/12/21/a-non-comprehensive-list-of-awesome-things-other-people-did-in-2015/), [2014](http://simplystatistics.org/2014/12/17/a-non-comprehensive-list-of-awesome-things-other-people-did-in-2014/), [2013](http://simplystatistics.org/2013/12/20/a-non-comprehensive-list-of-awesome-things-other-people-did-this-year/)). Like in previous years I'm making a list, again right off the top of my head. If you know of some, you should make your own list or add it to the comments! I have also avoided talking about stuff I worked on or that people here at Hopkins are doing because this post is supposed to be about other people’s awesome stuff. I write this post because a blog often feels like a place to complain, but we started Simply Stats as a place to be pumped up about the stuff people were doing with data._ + + +* Thomas Lin Pedersen created the [tweenr](https://github.com/thomasp85/tweenr) package for interpolating graphs in animations. Check out this awesome [logo](https://twitter.com/thomasp85/status/809896220906897408) he made with it. +* Yihui Xie is still blowing away everything he does. First it was [bookdown](https://bookdown.org/yihui/bookdown/) and then the yolo feature in [xaringan](https://github.com/yihui/xaringan) package. +* J Alammar built this great [visual introduction to neural networks](https://jalammar.github.io/visual-interactive-guide-basics-neural-networks/) +* Jenny Bryan is working literal world wonders with legos to teach functional programming. I loved her [Data Rectangling](https://speakerdeck.com/jennybc/data-rectangling) talk. The analogy between exponential families and data frames is so so good. +* Hadley Wickham's book on [R for data science](http://r4ds.had.co.nz/) is everything you'd expect. Super clear, great examples, just a really nice book. +* David Robinson is a machine put on this earth to create awesome data science stuff. Here is [analyzing Trump's tweets](http://varianceexplained.org/r/trump-tweets/) and here he is on [empirical Bayes modeling explained with baseball](http://varianceexplained.org/r/hierarchical_bayes_baseball/). +* Julia Silge and David created the [tidytext](https://cran.r-project.org/web/packages/tidytext/index.html) package. This is a holy moly big contribution to NLP in R. They also have a killer [book on tidy text mining](http://tidytextmining.com/). +* Julia used the package to do this [fascinating post](http://juliasilge.com/blog/Reddit-Responds/) on mining Reddit after the election. +* It would be hard to pick just five different major contributions from JJ Allaire (great interview [here](https://www.rstudio.com/rviews/2016/10/12/interview-with-j-j-allaire/)), Joe Cheng, and the rest of the Rstudio folks. Rstudio is absolutely _churning_ out awesome stuff at a rate that is hard to keep up with. I loved [R notebooks](https://blog.rstudio.org/2016/10/05/r-notebooks/) and have used them extensively for teaching. +* Konrad Kording and Brett Mensh full on mike dropped on how to write a paper with their [10 simple rules piece](http://biorxiv.org/content/early/2016/11/28/088278) Figure 1 from that paper should be affixed to the office of every student/faculty in the world permanently. +* Yaniv Erlich just can't stop himself from doing interesting things like [seeq.io](https://seeq.io/) and [dna.land](https://dna.land/). +* Thomaz Berisa and Joe Pickrell set up a freaking [Python API for genomics projects](https://medium.com/the-seeq-blog/start-a-human-genomics-project-with-a-few-lines-of-code-dde90c4ef68#.g64meyjim). +* DataCamp continues to do great things. I love their [DataChats](https://www.datacamp.com/community/blog/an-interview-with-david-robinson-data-scientist-at-stack-overflow) series and they have been rolling out tons of new courses. +* Sean Rife and Michele Nuijten created [statcheck.io](http://statcheck.io/) for checking papers for p-value calculation errors. This was all over the press, but I just like the site as a dummy proofing for myself. +* This was the artificial intelligence [tweet of the year](https://twitter.com/notajf/status/795717253505413122) +* I loved seeing PLoS Genetics start a policy of looking for papers in [biorxiv](http://blogs.plos.org/plos/2016/10/the-best-of-both-worlds-preprints-and-journals/). +* Matthew Stephens [post](https://medium.com/@biostatistics/guest-post-matthew-stephens-on-biostatistics-pre-review-and-reproducibility-a14a26d83d6f#.usisi7kd3) on his preprint getting pre-accepted and reproducibility is also awesome. Preprints are so hot right now! +* Lorena Barba made this amazing [reproducibility syllabus](https://hackernoon.com/barba-group-reproducibility-syllabus-e3757ee635cf#.2orb46seg) then [won the Leamer-Rosenthal prize](https://twitter.com/LorenaABarba/status/809641955437051904) in open science. +* Colin Dewey continues to do just stellar stellar work, this time on [re-annotating genomics samples](http://biorxiv.org/content/early/2016/11/30/090506). This is one of the key open problems in genomics. +* I love FlowingData sooooo much. Here is one on [the changing American diet](http://flowingdata.com/2016/05/17/the-changing-american-diet/). +* If you like computational biology and data science and like _super_ detailed reports of meetings/talks you [MIchael Hoffman](https://twitter.com/michaelhoffman) is your man. How he actually summarizes that much information in real time is still beyond me. +* I really really wish I had been at Alyssa Frazee's talk at startup.ml but loved this [review of it](http://www.win-vector.com/blog/2016/09/adversarial-machine-learning/). Sampling, inverse probability weighting? Love that stats flavor! +* I have followed Cathy O'Neil for a long time in her persona as [mathbabedotorg](https://twitter.com/mathbabedotorg) so it is no surprise to me that her new book [Weapons of Math Descruction](https://www.amazon.com/dp/B019B6VCLO/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1) is so good. One of the best works on the ethics of data out there. +* A related and very important piece is on [Machine bias in sentencing](https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing) by Julia Angwin, Jeff Larson, Surya Mattu and Lauren Kirchner at ProPublica. +* Dimitris Rizopolous created this stellar [integrated Shiny app](http://iprogn.blogspot.com/2016/03/an-integrated-shiny-app-for-course-on.html) for his repeated measures class. I wish I could build things half this nice. +* Daniel Engber's piece on [Who will debunk the debunkers?](http://fivethirtyeight.com/features/who-will-debunk-the-debunkers/) at fivethirtyeight just keeps getting more relevant. +* I rarely am willing to watch a talk posted on the internet, but [Amelia McNamara's talk on seeing nothing](https://www.youtube.com/watch?v=hps9r7JZQP8) was an exception. Plus she talks so fast #jealous. +* Sherri Rose's post on [economic diversity in the academy](http://drsherrirose.com/economic-diversity-and-the-academy-statistical-science) focuses on statistics but should be required reading for anyone thinking about diversity. Everything about it is impressive. +* If you like your data science with a side of Python you should definitely be checking out Jake Vanderplas's [data science handbook](http://shop.oreilly.com/product/0636920034919.do) and the associated [Jupyter notebooks](https://github.com/jakevdp/PythonDataScienceHandbook). +* I love Thomas Lumley [being snarky](http://www.statschat.org.nz/2016/12/19/sauna-and-dementia/) about the stats news. Its a guilty pleasure. If he ever collected them into a book I'd buy it (hint Thomas :)). +* Dorothy Bishop's blog is one of the ones I read super regularly. Her post on [When is a replication a replication](http://deevybee.blogspot.com/2016/12/when-is-replication-not-replication.html) is just one example of her very clearly explaining a complicated topic in a sensible way. I find that so hard to do and she does it so well. +* Ben Goldacre's crowd is doing a bunch of interesting things. I really like their [OpenPrescribing](https://openprescribing.net/) project. +* I'm really excited to see what Elizabeth Rhodes does with the experimental design for the [Ycombinator Basic Income Experiment](http://blog.ycombinator.com/moving-forward-on-basic-income/). +* Lucy D'Agostino McGowan made this [amazing explanation](http://www.lucymcgowan.com/hill-for-data-scientists.html) of Hill's criterion using xckd. +* It is hard to overstate how good Leslie McClure's blog is. This post on [biostatistics is public health](https://statgirlblog.wordpress.com/2016/09/16/biostatistics-is-public-health/) should be read aloud at every SPH in the US. +* The ASA's [statement on p-values](http://amstat.tandfonline.com/doi/abs/10.1080/00031305.2016.1154108) is a really nice summary of all the issues around a surprisngly controversial topic. Ron Wasserstein and Nicole Lazar did a great job putting it together. +* I really liked [this piece](http://jama.jamanetwork.com/article.aspx?articleId=2513561&guestAccessKey=4023ce75-d0fb-44de-bb6c-8a10a30a6173) on the relationship between income and life expectancy by Raj Chetty and company. +* Christie Aschwanden continues to be the voice of reason on the [statistical crises in science](http://fivethirtyeight.com/features/failure-is-moving-science-forward/). + +That's all I have for now, I know I'm missing things. Maybe my New Year's resolution will be to keep better track of the awesome things other people are doing :). diff --git a/_posts/2016-12-29-some-stress-reducers.md b/_posts/2016-12-29-some-stress-reducers.md new file mode 100644 index 0000000..134a671 --- /dev/null +++ b/_posts/2016-12-29-some-stress-reducers.md @@ -0,0 +1,32 @@ +--- +title: Some things I've found help reduce my stress around science +author: jeff +layout: post +comments: true +--- + +Being a scientist can be pretty stressful for any number of reasons, from the peer review process, to getting funding, to [getting blown up on the internet](http://simplystatistics.org/2015/11/16/so-you-are-getting-crushed-on-the-internet-the-new-normal-for-academics/). + +Like a lot of academics I suffer from a lot of stress related to my own high standards and the imposter syndrome that comes from not meeting them on a regular basis. I was just reading through the excellent material in Lorena Barba's class on [essential skills in reproducibility](https://barbagroup.github.io/essential_skills_RRC/) and came across this [set of slides](http://www.stat.berkeley.edu/~stark/Seminars/reproNE16.htm#1) by Phillip Stark. The one that caught my attention said: + +> If I say just trust me and I'm wrong, I'm untrustworthy. +> If I say here's my work and it's wrong, I'm honest, human, and serving scientific progress. + +I love this quote because it shows how being open about both your successes and failures makes it less stressful to be a scientist. Inspired by this quote I decided to make a list of things that I've learned through hard experience do not help me with my own imposter syndrome and do help me to feel less stressed out about my science. + +1. _Put everything out in the open._ We release all of our software, data, and analysis scripts. This has led to almost exclusively positive interactions with people as they help us figure out good and bad things about our work. +2. _Admit mistakes quickly._ Since my code/data are out in the open I've had people find little bugs and big whoa this is bad bugs in my code. I used to freak out when that happens. But I found the thing that minimizes my stress is to just quickly admit the error and submit updates/changes/revisions to code and papers as necessary. +3. _Respond to requests for support at my own pace._ I try to be as responsive as I can when people email me about software/data/code/papers of mine. I used to stress about doing this *right away* when I would get the emails. I still try to be prompt, but I don't let that dominate my attention/time. I also prioritize things that are wrong/problematic and then later handle the requests for free consulting every open source person gets. +4. _Treat rejection as a feature not a bug._ This one is by far the hardest for me but preprints have helped a ton. The academic system is _designed_ to be critical. That is a good thing, skepticism is one of the key tenets of the scientific process. It took me a while to just plan on one or two rejections for each paper, one or two or more rejections for each grant, etc. But now that I plan on the rejection I find I can just focus on how to steadily move forward and constructively address criticism rather than taking it as a personal blow. +5. _Don't argue with people on the internet, especially on Twitter._ This is a new one for me and one I'm having to practice hard every single day. But I've found that I've had very few constructive debates on Twitter. I also found that this is almost purely negative energy for me and doesn't help me accomplish much. +6. _Redefine success._ I've found that if I recalibrate what success means to include accomplishing tasks like peer reviewing papers, getting letters of recommendation sent at the right times, providing support to people I mentor, and the submission rather than the success of papers/grants then I'm much less stressed out. +7. _Don't compare myself to other scientists._ It is [very hard to get good evaluation in science](http://simplystatistics.org/2015/02/09/the-trouble-with-evaluating-anything/) and I'm extra bad at self-evaluation. Scientists are good in many different dimensions and so whenever I pick a one dimensional summary and compare myself to others there are always people who are "better" than me. I find I'm happier when I set internal, short term goals for myself and only compare myself to them. +8. _When comparing, at least pick a metric I'm good at._ I'd like to claim I never compare myself to others, but the reality is I do it more than I'd like. I've found one way to not stress myself out for my own internal comparisons is to pick metrics I'm good at - even if they aren't the "right" metrics. That way at least if I'm comparing I'm not hurting my own psyche. +9. _Let myself be bummed sometimes._ Some days despite all of that I still get the imposter syndrome feels and can't get out of the funk. I used to beat myself up about those days, but now I try to just build that into the rhythm of doing work. +10. _Try very hard to be positive in my interactions._ This is another hard one, because it is important to be skeptical/critical as a scientist. But I also try very hard to do that in as productive a way as possible. I try to assume other people are doing the right thing and I try very hard to stay positive or neutral when writing blog posts/opinion pieces, etc. +11. _Realize that giving credit doesn't take away from me._ In my research career I have worked with some extremely [generous](http://genomics.princeton.edu/storeylab/) [mentors](http://rafalab.github.io/). They taught me to always give credit whenever possible. I also learned from [Roger](http://www.biostat.jhsph.edu/~rpeng/) that you can give credit and not lose anything yourself, in fact you almost always gain. Giving credit is low cost but feels really good so is a nice thing to help me feel better. + + +The last thing I'd say is that having a blog has helped reduce my stress, because sometimes I'm having a hard time getting going on my big project for the day and I can quickly write a blog post and still feel like I got something done... + + diff --git a/_posts/2017-01-09-nssd-episode-30.md b/_posts/2017-01-09-nssd-episode-30.md new file mode 100644 index 0000000..75dd0de --- /dev/null +++ b/_posts/2017-01-09-nssd-episode-30.md @@ -0,0 +1,31 @@ +--- +author: roger +layout: post +title: Not So Standard Deviations Episode 30 - Philately and Numismatology +--- + +Hilary and I follow up on open data and data sharing in government. They also discuss artificial intelligence, self-driving cars, and doing your taxes in R. + +If you have questions you’d like Hilary and me to answer, you can send them to nssdeviations @ gmail.com or tweet us at [@NSSDeviations](https://twitter.com/nssdeviations). + +Show notes: + +* Lucy D’Agostino McGowan (@LucyStats) made a [great translation of Hill’s criteria using XKCD comics](http://www.lucymcgowan.com/hill-for-data-scientists.html) + +* [Lucy’s web page](http://www.lucymcgowan.com) + +* [Preparing for the Future of Artificial Intelligence](https://www.whitehouse.gov/sites/default/files/whitehouse_files/microsites/ostp/NSTC/preparing_for_the_future_of_ai.pdf) + +* [Partially Derivative White House Special – with DJ Patil, US Chief Data Scientist](http://12%20Dec%202016%20White%20House%20Special%20with%20DJ%20Patil,%20US%20Chief%20Data%20Scientist) + +* [Not So Standard Deviations – Standards are Like Toothbrushes – with with Daniel Morgan, Chief Data Officer for the U.S. Department of Transportation and Terah Lyons, Policy Advisor to the Chief Technology Officer of the U.S.](https://soundcloud.com/nssd-podcast/episode-29-standards-are-like-toothbrushes) + +* [Henry Gitner Philatelists](http://www.hgitner.com) + +* [Some Pioneers of Modern Statistical Theory: A Personal Reflection by Sir David R. Cox](https://drive.google.com/file/d/0B678uTpUfn80a2RkOUc5LW51cVU/view?usp=sharing) + + +[Download the audio for this episode](https://soundcloud.com/nssd-podcast/episode-30-philately-and-numismatology) + +Listen here: + diff --git a/_posts/2017-01-17-effort-report-episode-23.md b/_posts/2017-01-17-effort-report-episode-23.md new file mode 100644 index 0000000..826d329 --- /dev/null +++ b/_posts/2017-01-17-effort-report-episode-23.md @@ -0,0 +1,23 @@ +--- +title: Interview with Al Sommer - Effort Report Episode 23 +author: roger +layout: post +--- + +My colleage [Elizabeth Matsui](https://twitter.com/elizabethmatsui) and I had a great opportunity to talk with Al Sommer on the [latest episode](http://effortreport.libsyn.com/23-special-guest-al-sommer) of our podcast [The Effort Report](http://effortreport.libsyn.com). Al is the former Dean of the Johns Hopkins Bloomberg School of Public Health and is Professor of Epidemiology and International Health at the School. He is (among other things) world reknown for his pioneering research in vitamin A deficiency and mortality in children. + +Al had some good bits of advice for academics and being successful in academia. + +> What you are excited about and interested in at the moment, you're much more likely to be succesful at---because you're excited about it! So you're going to get up at 2 in the morning and think about it, you're going to be putting things together in ways that nobody else has put things together. And guess what? When you do that you're more succesful [and] you actual end up getting academic promotions. + +On the slow rate of progress: + +> It took ten years, after we had seven randomized trials already to show that you get this 1/3 reduction in child mortality by giving them two cents worth of vitamin A twice a year. It took ten years to convince the child survival Nawabs of the world, and there are still some that don't believe it. + +On working overseas: + +> It used to be true [that] it's a lot easier to work overseas than it is to work here because the experts come from somewhere else. You're never an expert in your own home. + +You can listen to the entire episode here: + + \ No newline at end of file diff --git a/_posts/2017-01-18-data-prototyping-class.md b/_posts/2017-01-18-data-prototyping-class.md new file mode 100644 index 0000000..87b2b00 --- /dev/null +++ b/_posts/2017-01-18-data-prototyping-class.md @@ -0,0 +1,25 @@ +--- +title: Got a data app idea? Apply to get it prototyped by the JHU DSL! +author: jeff +layout: post +comments: true +--- + + + +Last fall we ran the first iteration of a class at the [Johns Hopkins Data Science Lab](http://jhudatascience.org/) where we teach students to build data web-apps using Shiny, R, GoogleSheets and a number of other technologies. Our goals were to teach students to build data products, to reduce friction for students who want to build things with data, and to help people solve important data problems with web and SMS apps. + +We are going to be running a second iteration of our program from March-June this year. We are looking for awesome projects for students to build that solve real world problems. We are particularly interested in projects that could have a positive impact on health but are open to any cool idea. We generally build apps that are useful for: + +* __Data donation__ - if you have a group of people you would like to donate data to your project. +* __Data collection__ - if you would like to build an app for collecting data from people. +* __Data visualziation__ - if you have a data set and would like to have a web app for interacting with the data +* __Data interaction__ - if you have a statistical or machine learning model and you would like a web interface for it. + +But we are interested in any consumer-facing data product that you might be interested in having built. We want you to submit your wildest, most interesting ideas and we’ll see if we can get them built for you. + +We are hoping to solicit a large number of projects and then build as many as possible. The best part is that we will build the prototype for you for free! If you have an idea of something you'd like built please submit it to this [Google form](https://docs.google.com/forms/d/1UPl7h8_SLw4zNFl_I9li_8GN14gyAEtPHtwO8fJ232E/edit?usp=forms_home&ths=true). + +Students in the class will select projects they are interested in during early March. We will let you know if your idea was selected for the program by mid-March. If you aren't selected you will have the opportunity to roll your submission over to our next round of prototyping. + +I'll be writing a separate post targeted at students, but if you are interested in being a data app prototyper, sign up [here](http://jhudatascience.org/prototyping_students.html). diff --git a/_posts/2017-01-19-what-is-artificial-intelligence.md b/_posts/2017-01-19-what-is-artificial-intelligence.md new file mode 100644 index 0000000..a989975 --- /dev/null +++ b/_posts/2017-01-19-what-is-artificial-intelligence.md @@ -0,0 +1,353 @@ +--- +title: What is artificial intelligence? A three part definition +author: jeff +layout: post +comments: true +--- + +_Editor's note: This is the first chapter of a book I'm working on called [Demystifying Artificial Intelligence](https://leanpub.com/demystifyai/). The goal of the book is to demystify what modern AI is and does for a general audience. So something to smooth the transition between AI fiction and highly mathematical descriptions of deep learning. I'm developing the book over time - so if you buy the book on Leanpub know that there is only one chaper in there so far, but I'll be adding more over the next few weeks and you get free updates. The cover of the book was inspired by this [amazing tweet](https://twitter.com/notajf/status/795717253505413122) by Twitter user [@notajf](https://twitter.com/notajf/). Feedback is welcome and encouraged!_ + +What is artificial intelligence? +================================ + +> "If it looks like a duck and quacks like a duck but it needs +> batteries, you probably have the wrong abstraction" [Derick +> Bailey](https://lostechies.com/derickbailey/2009/02/11/solid-development-principles-in-motivational-pictures/) + +This book is about artificial intelligence. The term "artificial +intelligence" or "AI" has a long and convoluted history (Cohen and +Feigenbaum 2014). It has been used by philosophers, statisticians, +machine learning experts, mathematicians, and the general public. This +historical context means that when people say *artificial intelligence* +the term is loaded with one of many potential different meanings. + +Humanoid robots +--------------- + +Before we can demystify artificial intelligence it is helpful to have +some context for what the word means. When asked about artificial +intelligence, most people's imagination leaps immediately to images of +robots that can act like and interact with humans. Near-human robots +have long been a source of fascination by humans have appeared in +cartoons like the *Jetsons* and science fiction like *Star Wars*. More +recently, subtler forms of near-human robots with artificial +intelligence have played roles in movies like *Her* and *Ex machina*. + + + +The type of artificial intelligence that can think and act like a human +is something that experts call artificial general intelligence +(Wikipedia contributors 2017a). + +> is the intelligence of a machine that could successfully perform any +> intellectual task that a human being can + +There is an understandable fascination and fear associated with robots, +created by humans, but evolving and thinking independently. While this +is a major area of ressearch (Laird, Newell, and Rosenbloom 1987) and of +course the center of most people's attention when it comes to AI, there +is no near term possibility of this type of intelligence (Urban, n.d.). +There are a number of barriers to human-mimicking AI from difficulty +with robotics (Couden 2015) to needed speedups in computational power +(Langford, n.d.). + +One of the key barriers is that most current forms of the computer +models behind AI are trained to do one thing really well, but can not be +applied beyond that narrow task. There are extremely effective +artificial intelligence applications for translating between languages +(Wu et al. 2016), for recognizing faces in images (Taigman et al. 2014), +and even for driving cars (Santana and Hotz 2016). + +But none of these technologies are generalizable across the range of +tasks that most adult humans can accomplish. For example, the AI +application for recognizing faces in images can not be directly applied +to drive cars and the translation application couldn't recognize a +single image. While some of the internal technology used in the +applications is the same, the final version of the applications can't be +transferred. This means that when we talk about artificial intelligence +we are not talking about a general purpose humanoid replacement. +Currently we are talking about technologies that can typically +accomplish one or two specific tasks that a human could accomplish. + +Cognitive tasks +--------------- + +While modern AI applications couldn't do everything that an adult could +do (Baciu and Baciu 2016), they can perform individual tasks nearly as +well as a human. There is a second commonly used definition of +artificial intelligence that is considerably more narrow (Wikipedia +contributors 2017b) + +> ... the term "artificial intelligence" is applied when a machine +> mimics "cognitive" functions that humans associate with other human +> minds, such as "learning" and "problem solving". + +This definition encompasses applications like machine translation and +facial recognition. They are "cognitive" functions that are generally +usually only performed by humans. A difficulty with this definition is +that it is relative. People refer to machines that can do tasks that we +thought humans could only do as artificial intelligence. But over time, +as we become used to machines performing a particular task it is no +longer surprising and we stop calling it artificial intelligence. John +McCarthy, one of the leading early figures in artificial intelligence +said (Vardi 2012): + +> As soon as it works, no one calls it AI anymore... + +As an example, when you send a letter in the mail, there is a machine +that scans the writing on the letter. A computer then "reads" the +characters on the front of the letter. The computer reads the characters +in several steps - the color of each pixel in the picture of the letter +is stored in a data set on the computer. Then the computer uses an +algorithm that has been built using thousands or millions of other +letters to take the pixel data and turn it into predictions of the +characters in the image. Then the characters are identified as +addresses, names, zipcodes, and other relevant pieces of information. +Those are then stored in the computer as text which can be used for +sorting the mail. + +This task used to be considered "artificial intelligence" (Pavlidis, +n.d.). It was surprising that a computer could perform the tasks of +recognizing characters and addresses just based on a picture of the +letter. This task is now called "optical character recognition" +(Wikipedia contributors 2016). Many tutorials on the algorithms behind +machine learning begin with this relatively simple task (Google +Tensorflow Team, n.d.). Optical character recognition is now used in a +wide range of applications including in Google's effort to digitize +millions of books (Darnton 2009). + +Since this type of algorithm has become so common it is no longer called +"artificial intelligence". This transition happened becasue we no longer +think it is surprising that computers can do this task - so it is no +longer considered intelligent. This process has played out with a number +of other technologies. Initially it is thought that only a human can do +a particular cognitive task. As computers become increasingly proficient +at that task they are called artificially intelligent. Finally, when +that task is performed almost exclusively by computers it is no longer +considered "intelligent" and the boundary moves. + + + +Over the last two decades tasks from optical character recognition, to +facial recognition in images, to playing chess have started as +artificially intelligent applications. At the time of this writing there +are a number of technologies that are currently on the boundary between +doable only by a human and doable by a computer. These are the tasks +that are considered AI when you read about the term in the media. +Examples of tasks that are currently considered "artificial +intelligence" include: + +- Computers that can drive cars +- Computers that can identify human faces from pictures +- Computers that can translate text from one language to another +- Computers that can label pictures with text descriptions + +Just as it used to be with optical character recognition, self-driving +cars and facial recognition are tasks that still surprise us when +performed by a computer. So we still call them artificially intelligent. +Eventually, many or most of these tasks will be performed nearly +exclusively by computers and we will no longer think of them as +components of computer "intelligence". To go a little further we can +think about any task that is repetitive and performed by humans. For +example, picking out music that you like or helping someone buy +something at a store. An AI can eventually be built to do those tasks +provided that: (a) there is a way of measuring and storing information +about the tasks and (b) there is technology in place to perform the task +if given a set of computer instructions. + +The more narrow definition of AI is used colloquially in the news to +refer to new applications of computers to perform tasks previously +thought impossible. It is important to know both the definition of AI +used by the general public and the more narrow and relative definition +used to describe modern applications of AI by companies like Google and +Facebook. But neither of these definitions is satisfactory to help +demystify the current state of artificial intelligence applications. + +A three part definition +----------------------- + +The first definition describes a technology that we are not currently +faced with - fully functional general purpose artificial intelligence. +The second definition suffers from the fact that it is relative to the +expectations of people discussing applications. For this book, we need a +definition that is concrete, specific, and doesn't change with societal +expectations. + +We will consider specific examples of human-like tasks that computers +can perform. So we will use the definition that artificial intelligence +requires the following components: + +1. *The data set* : A of data examples that can be used to train a + statistical or machine learning model to make predictions. +2. *The algorithm* : An algorithm that can be trained based on the data + examples to take a new example and execute a human-like task. +3. *The interface* : An interface for the trained algorithm to receive + a data input and execute the human like task in the real world. + +This definition encompases optical character recognition and all the +more modern examples like self driving cars. It is also intentionally +broad, covering even examples where the data set is not large or the +algorithm is not complicated. We will use our definition to break down +modern artificial intelligence applications into their constituitive +parts and make it clear how the computer represents knowledge learned +from data examples and then applies that knowledge. + +As one example, consider Amazon Echo and Alexa - an application +currently considered to be artificially intelligent (Nuñez, n.d.). This +combination meets our definition of artificially intelligent since each +of the components is in place. + +1. *The data set* : The large set of data examples consist of all the + recordings that Amazon has collected of people talking to their + Amazon devices. +2. *The machine learning algorithm* : The Alexa voice service (Alexa + Developers 2016) is a machine learning algorithm trained using the + previous recordings of people talking to Amazon devices. +3. *The interface* : The interface is the Amazon Echo (Amazon Inc 2016) + a speaker that can record humans talking to it and respond with + information or music. + + + +When we break down artificial intelligence into these steps it makes it +clearer why there has been such a sudden explosion of interest in +artificial intelligence over the last several years. + +First, the cost of data storage and collection has gone down steadily +(Irizarry, n.d.) but dramatically (Quigley, n.d.) over the last several +years. As the costs have come down, it is increasingly feasible for +companies, governments, and even individuals to store large collections +of data (Component 1 - *The Data*). To take advantage of these huge +collections of data requires incredibly flexible statistical or machine +learning algorithms that can capture most of the patterns in the data +and re-use them for prediction. The most common type of algorithms used +in modern artificial intelligence are something called "deep neural +networks". These algorithms are so flexible they capture nearly all of +the important structure in the data. They can only be trained well if +huge data sets exist and computers are fast enough. Continual increases +in computing speed and power over the last several decades now make it +possible to apply these models to use collections of data (Component 2 - +*The Algorithm*). + +Finally, the most underappreciated component of the AI revolution does +not have to do with data or machine learning. Rather it is the +development of new interfaces that allow people to interact directly +with machine learning models. For a number of years now, if you were an +expert with statistical and machine learning software it has been +possible to build highly accurate predictive models. But if you were a +person without technical training it was not possible to directly +interact with algorithms. + +Or as statistical experts Diego Kuonen and Rafael Irizarry have put it: + +> The big in big data refers to importance, not size + +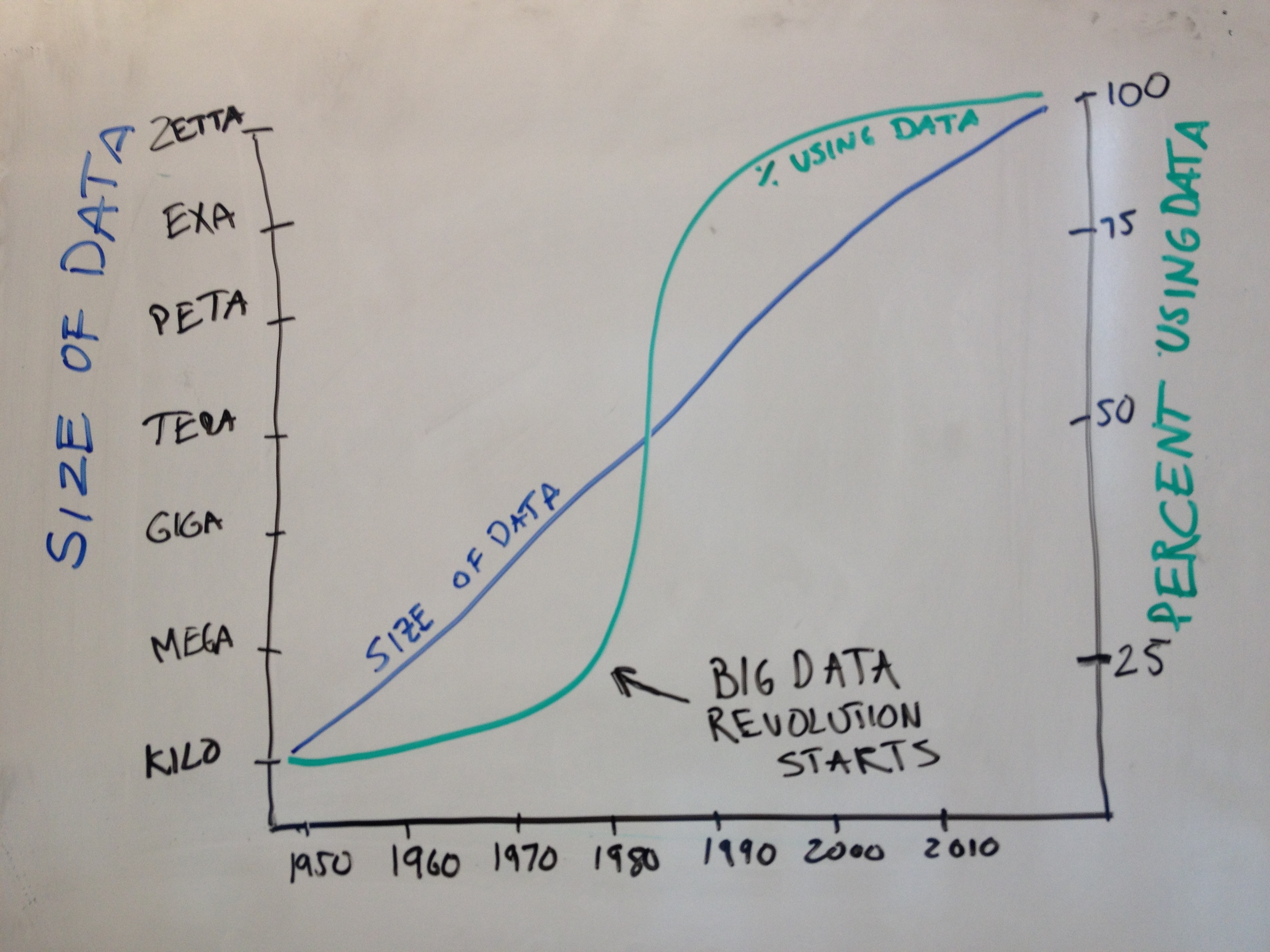 + +The explosion of interfaces for regular, non-technical people to +interact with machine learning is an underappreciated driver of the AI +revolution of the last several years. Artificial intelligence can now +power labeling friends on Facebook, parsing your speech to your personal +assistant Siri or Google Assistant, or providing you with directions in +your car, or when you talk to your Echo. More recently sensors and +devices make it possible for the instructions created by a computer to +steer and drive a car. + +These interfaces now make it possible for hundreds of millions of people +to directly interact with machine learning algorithms. These algorithms +can range from exceedingly simple to mind bendingly complex. But the +common result is that the interface allows the computer to perform a +human-like action and makes it look like artificial intelligence to the +person on the other side. This interface explosion only promises to +accelerate as we are building sensors for both data input and behavior +output in objects from phones to refrigerators to cars (Component 3 - +*The interface*). + +This definition of artificial intelligence in three components will +allow us to demystify artificial intelligence applications from self +driving cars to facial recognition. Our goal is to provide a high-level +interface to the current conception of AI and how it can be applied to +problems in real life. It will include discussion and references to the +sophisticated models and data collection methods used by Facebook, +Tesla, and other companies. However, the book does not assume a +mathematical or computer science background and will attempt to explain +these ideas in plain language. Of course, this means that some details +will be glossed over, so we will attempt to point the interested reader +toward more detailed resources throughout the book. + +References +---------- + +Alexa Developers. 2016. “Alexa Voice Service.” ++ +Theranos promised to revolutionize blood testing and change the user experience behind the whole industry. Indeed the company had some fans (particularly amongst its [investor base](https://www.axios.com/tim-drapers-keeps-defending-theranos-2192078259.html)). However, after investigations by the Center for Medicare and Medicaid Services, the FDA, and an independent laboratory, it was found that Theranos's blood testing machine was wildly inconsistent and variable, leading to Theranos ultimately retracting all of its blood test results and cutting half its workforce. + +Homeopathy is not company specific, but is touted by many as an "alternative" treatment for many diseases, with many claiming that it "works for them". However, the NIH states quite clearly on its [web site](https://nccih.nih.gov/health/homeopathy) that "There is little evidence to support homeopathy as an effective treatment for any specific condition." + +Finally, companies like Coursera and Udacity in the education space have indeed produced products that people like, but in some instances have hit bumps in the road. Udacity conducted a brief experiment/program with San Jose State University that failed due to the large differences between the population that took online courses and the one that took them in person. Coursera has massive offerings from major universities (including my own) but has run into continuing [challenges with drop out](http://www.economist.com/news/special-report/21714173-alternative-providers-education-must-solve-problems-cost-and) and questions over whether the courses offered are suitable for job placement. + +## User Experience and Value + +In each of these four examples there is a consumer product that people love, often because they provide a great user experience. Take the fake news example--people love to read headlines from "trusted" news sources that agree with what they believe. With Theranos, people love to take a blood test that is not painful (maybe "love" is the wrong word here). With many consumer products companies, it is the user experience that defines the value of a product. Often when describing the user experience, you are simultaneously describing the value of the product. + +Take for example Uber. With Uber, you open an app on your phone, click a button to order a car, watch the car approach you on your phone with an estimate of how long you will be waiting, get in the car and go to your destination, and get out without having to deal with paying. If someone were to ask me "What's the value of Uber?" I would probably just repeat the description in the previous sentence. Isn't it obvious that it's better than the usual taxi experience? The same could be said for many companies that have recently come up: Airbnb, Amazon, Apple, Google. With many of the products from these companies, *the description of the user experience is a description of its value*. + +## Disruption Through User Experience + +In the example of Uber (and Airbnb, and Amazon, etc.) you could depict the relationship between the product, the user experience, and the value as such: + + + +Any changes that you can make to the product to improve the user experience will then improve the value that the product offers. Another way to say it is that the user experience serves as a *surrogate outcome* for the value. We can influence the UX and know that we are improving value. Furthermore, any measurements that we take on the UX (surveys, focus groups, app data) will serve as direct observations on the value provided to customers. + +New companies in these kinds of consumer product spaces can disrupt the incumbents by providing a much better user experience. When incumbents have gotten fat and lazy, there is often a sizable segment of the customer base that feels underserved. That's when new companies can swoop in to specifically serve that segment, often with a "worse" product overall (as in fewer features) and usually much cheaper. The Internet has made the "swooping in" much easier by [dramatically reducing transaction and distribution costs](https://stratechery.com/2015/netflix-and-the-conservation-of-attractive-profits/). Once the new company has a foothold, they can gradually work their way up the ladder of customer segments to take over the market. It's classic disruption theory a la [Clayton Christensen](http://www.claytonchristensen.com). + + +## When Value Defines the User Experience and Product + +There has been much talk of applying the classic disruption model to every space imaginable, but I contend that not all product spaces are the same. In particular, the four examples I described in the beginning of this post cover some of those different areas: + +* Medicine (Theranos, homeopathy) +* News (Facebook/fake news) +* Education (Coursera/Udacity) + +One thing you'll notice about these areas, particularly with medicine and education, is that they are all heavily regulated. The reason is because we as a community have decided that there is a minimum level of value that is required to be provided by entities in this space. That is, the value that a product offers is *defined first*, before the product can come to market. Therefore, the value of the product actually constrains the space of products that can be produced. We can depict this relationship as such: + + + +In classic regression modeling language, the value of a product must be "adjusted for" before examining the relationship between the product and the user experience. Naturally, as in any regression problem, when you adjust for a variable that is related to the product and the user experience, you reduce the overall variation in the product. + +In situations where the value defines the product and the user experience, there is much less room to maneuver for new entrants in the market. The reason is because they, like everyone else, are constrained by the value that is agreed upon by the community, usually in the form of regulations. + +When Theranos comes in and claims that it's going to dramatically improve the user experience of blood testing, that's great, but they must be constrained by the value that society demands, which is a certain precision and accuracy in its testing results. Companies in the online education space are welcome to disrupt things by providing a better user experience. Online offerings in fact do this by allowing students to take classes according to their own schedule, wherever they may live in the world. But we still demand that the students learn an agreed-upon set of facts, skills, or lessons. + +New companies will often argue that the things that we currently value are outdated or no longer valuable. Their incentive is to change the value required so that there is more room for new companies to enter the space. This is a good thing, but it's important to realize that this cannot happen solely through changes in the product. Innovative features of a product may help us to understand that we should be valuing different things, but ultimately the change in what we preceive as value occurs independently of any given product. + +When I see new companies enter the education, medicine, or news areas, I always hesitate a bit because I want some assurance that they will still provide the value that we have come to expect. In addition, with these particular areas, there is a genuine sense that failing to deliver on what we value could cause serious harm to individuals. However, I think the discussion that is provoked by new companies entering the space is always welcome because we need to constantly re-evaluate what we value and whether it matches the needs of our time. + diff --git a/_posts/2017-01-26-new-prototyping-class.md b/_posts/2017-01-26-new-prototyping-class.md new file mode 100644 index 0000000..e98d520 --- /dev/null +++ b/_posts/2017-01-26-new-prototyping-class.md @@ -0,0 +1,32 @@ +--- +title: New class - Data App Prototyping for Public Health and Beyond +author: jeff +layout: post +comments: true +--- + + +Are you interested in building data apps to help save the world, start the next big business, or just to see if you can? We are running a data app prototyping class for people interested in creating these apps. + +This will be a special topics class at JHU and is open to any undergrad student, grad student, postdoc, or faculty member at the university. We are also seeing if we can make the class available to people outside of JHU so even if you aren't at JHU but are interested you should let us know below. + +One of the principles of our approach is that anyone can prototype an app. Our class starts with some tutorials on Shiny and R. While we have no formal pre-reqs for the class you will have much more fun if you have the background equivalent to our Coursera classes: + +* [Data Scientist’s Toolbox](https://www.coursera.org/learn/data-scientists-tools) +* [R programming](https://www.coursera.org/learn/r-programming) +* [Building R packages](https://www.coursera.org/learn/r-packages) +* [Developing Data Products](https://www.coursera.org/learn/data-products) + +If you don't have that background you can take the classes online starting now to get up to speed! To see some examples of apps we will be building check out our [gallery](http://jhudatascience.org/data_app_gallery.html). + + +We will mostly be able to support development with R and Shiny but would be pumped to accept people with other kinds of development background - we just might not be able to give a lot of technical assistance. + + +As part of the course we are also working with JHU's [Fast Forward](https://ventures.jhu.edu/fastforward/) program to streamline and ease the process of starting a company around the app you build for the class. So if you have entrepreneurial ambitions, this is the class for you! + + +We are in the process of setting up the course times, locations, and enrollment cap. The class will run from March to May (exact dates TBD). To sign up for announcements about the class please fill out your information [here](http://jhudatascience.org/prototyping_students.html). + + + diff --git a/_posts/2017-01-31-data-into-numbers.md b/_posts/2017-01-31-data-into-numbers.md new file mode 100644 index 0000000..8c40b1d --- /dev/null +++ b/_posts/2017-01-31-data-into-numbers.md @@ -0,0 +1,153 @@ +--- +title: Turning data into numbers +author: jeff +layout: post +comments: true +--- + +_Editor's note: This is the third chapter of a book I'm working on called [Demystifying Artificial Intelligence](https://leanpub.com/demystifyai/). The goal of the book is to demystify what modern AI is and does for a general audience. So something to smooth the transition between AI fiction and highly mathematical descriptions of deep learning. I'm developing the book over time - so if you buy the book on Leanpub know that there are only three chapters in there so far, but I'll be adding more over the next few weeks and you get free updates. The cover of the book was inspired by this [amazing tweet](https://twitter.com/notajf/status/795717253505413122) by Twitter user [@notajf](https://twitter.com/notajf/). Feedback is welcome and encouraged!_ + + +> "It is a capital mistake to theorize before one has data." Arthur Conan Doyle + +Data, data everywhere +--------------------- + +I already have some data about you. You are reading this book. Does that seem like data? It’s just something you did, that’s not data is it? But if I collect that piece of information about you, it actually tells me a surprising amount. It tells me you have access to an internet connection, since the only place to get the book is online. That in turn tells me something about your socioeconomic status and what part of the world you live in. It also tells me that you like to read, which suggests a certain level of education. + +Whether you know it or not, everything you do produces data - from the websites you read to the rate at which your heart beats. Until pretty recently, most of the data you produced wasn’t collected, it floated off unmeasured. Data were painstakingly gathered by scientists one number at a time in small experiments with a few people. This laborious process meant that data were expensive and time-consuming to collect. Yet many of the most amazing scientific discoveries over the last two centuries were squeezed from just a few data points. But over the last two decades, the unit price of data has dramatically dropped. New technologies touching every aspect of our lives from our money, to our health, to our social interactions have made data collection cheap and easy. + +To give you an idea of how steep the drop in the price of data has been, in 1967 Stanley Milgram did an experiment to determine the number of degrees of separation between two people in the U.S. (Travers and Milgram 1969). In his experiment he sent 296 letters to people in Omaha, Nebraska and Wichita, Kansas. The goal was to get the letters to a specific person in Boston, Massachusetts. The trick was people had to send the letters to someone they knew, and they then sent it to someone they knew and so on. At the end of the experiment, only 64 letters made it to the individual in Boston. On average, the letters had gone through 6 people to get there. + +This is an idea that is so powerful it even became part of the popular consciousness. For example it is the foundation of the internet meme "the 6-degrees of Kevin Bacon" (Wikipedia contributors 2016a) - the idea that if you take any actor and look at the people they have been in movies with, then the people those people have been in movies with, it will take you at most six steps to end up at the actor Kevin Bacon. This idea, despite its popularity was originally studied by Milgram using only 64 data points. A 2007 study updated that number to “7 degrees of Kevin Bacon”. The study was based on 30 billion instant messaging conversations collected over the course of a month or two with the same amount of effort (Leskovec and Horvitz 2008). + +Once data started getting cheaper to collect, it got cheaper fast. Take another example, the human genome. The genome is the unique DNA code in every one of your cells. It consists of a set of 3 billion letters that is unique to you. By many measures, the race to be the first group to collect all 3 billion letters from a single person kicked off the data revolution in biology. The project was completed in 2000 after a decade of work and $3 billion to collect the 3 billion letters in the first human genome (Venter et al. 2001). This project was actually a stunning success, most people thought it would be much more expensive. But just over a decade later, new technology means that we can now collect all 3 billion letters from a person’s genome for about $1,000 in about a week (“The Cost of Sequencing a Human Genome,” n.d.), soon it may be less than $100 (Buhr 2017). + +You may have heard that this is the era of “big data” from The Economist or The New York Times. It is really the era of cheap data collection and storage. Measurements we never bothered to collect before are now so easy to obtain that there is no reason not to collect them. Advances in computer technology also make it easier to store huge amounts of data digitally. This may not seem like a big deal, but it is much easier to calculate the average of a bunch of numbers stored electronically than it is to calculate that same average by hand on a piece of paper. Couple these advances with the free and open distribution of data over the internet and it is no surprise that we are awash in data. But tons of data on their own are meaningless. It is understanding and interpreting the data where the real advances start to happen. + +This explosive growth in data collection is one of the key driving influences behind interest in artificial intelligence. When teaching computers to do something that only humans could do previously, it helps to have lots of examples. You can then use statistical and machine learning models to summarize that set of examples and help a computer make decisions what to do. The more examples you have, the more flexible your computer model can be in making decisions, and the more "intelligent" the resulting application. + +What is data? +------------- + +### Tidy data + +"What is data"? Seems like a relatively simple question. In some ways this question is easy to answer. According to [Wikipedia](https://en.wikipedia.org/wiki/Data): + +> Data (/ˈdeɪtə/ day-tə, /ˈdætə/ da-tə, or /ˈdɑːtə/ dah-tə)\[1\] is a set of values of qualitative or quantitative variables. An example of qualitative data would be an anthropologist's handwritten notes about her interviews with people of an Indigenous tribe. Pieces of data are individual pieces of information. While the concept of data is commonly associated with scientific research, data is collected by a huge range of organizations and institutions, ranging from businesses (e.g., sales data, revenue, profits, stock price), governments (e.g., crime rates, unemployment rates, literacy rates) and non-governmental organizations (e.g., censuses of the number of homeless people by non-profit organizations). + +When you think about data, you probably think of orderly sets of numbers arranged in something like an Excel spreadsheet. In the world of data science and machine learning this type of data has a name - "tidy data" (Wickham and others 2014). Tidy data has the properties that all measured quantities are represented by numbers or character strings (think words). The data are organized such that. + +1. Each variable you measured is in one column +2. Each different measurement of that variable is in a different row +3. There is one data table for each "type" of variable. +4. If there are multiple tables then they are linked by a common ID. + +This idea is borrowed from data management schemas that have long been used for storing data in databases. Here is an example of a tidy data set of swimming world records. + +| year| time| sex | +|-----:|-----:|:----| +| 1905| 65.8| M | +| 1908| 65.6| M | +| 1910| 62.8| M | +| 1912| 61.6| M | +| 1918| 61.4| M | +| 1920| 60.4| M | +| 1922| 58.6| M | +| 1924| 57.4| M | +| 1934| 56.8| M | +| 1935| 56.6| M | + +This type of data, neat, organized and nicely numeric is not the kind of data people are talking about when they say the "era of big data". Data almost never start their lives in such a neat and organized format. + +### Raw data + +The explosion of interest in AI has been powered by a variety of types of data that you might not even think of when you think of "data". The data might be pictures you take and upload to social media, the text of the posts on that same platform, or the sound captured from your voice when you speak to your phone. + +Social media and cell phones aren't the only area where data is being collected more frequently. Speed cameras on roads collect data on the movement of cars, electronic medical records store information about people's health, wearable devices like Fitbit collect information on the activity of people. GPS information stores the location of people, cars, boats, airplanes, and an increasingly wide array of other objects. + +Images, voice recordings, text files, and GPS coordinates are what experts call "raw data". To create an artificial intelligence application you need to begin with a lot of raw data. But as we discussed in the simple AI example from the previous chapter - a computer doesn't understand raw data in its natural form. It is not always immediately obvious how the raw data can be turned into numbers that a computer can understand. For example, when an artificial intelligence works with a picture the computer doesn't "see" the picture file itself. It sees a set of numbers that represent that picture and operates on those numbers. The first step in almost every artificial intelligence application is to "pre-process" the data - to take the image files or the movie files or the text of a document and turn it into numbers that a computer can understand. Then those numbers can be fed into algorithms that can make predictions and ultimately be used to make an interface look intelligent. + +Turning raw data into numbers +----------------------------- + +So how do we convert raw data into a form we can work with? It depends on what type of measurement or data you have collected. Here I will use two examples to explain how you can convert images and the text of a document into numbers that an algorithm can be applied to. + +### Images + +Suppose that we were developing an AI to identify pictures of the author of this book. We would need to collect a picture of the author - maybe an embarrassing one. + + + +This picture is made of pixels. You can see that if you zoom in very close on the image and look more closely. You can see that the image consists of many hundreds of little squares, each square just one color. Those squares are called pixels and they are one step closer to turning the image into numbers. + + + +You can think of each pixel like a dot of color. Let's zoom in a little bit more and instead of showing each pixel as a square show each one as a colored dot. + + + +Imagine we are going to build an AI application on the basis of lots of images. Then we would like to turn a set of images into "tidy data". As described above a tidy data set is defined as the following. + +1. Each variable you measured is in one column +2. Each different measurement of that variable is in a different row +3. There is one data table for each "type" of variable. +4. If there are multiple tables then they are linked by a common ID. + +A translation of tidy data for a collection of images would be the following. + +1. *Variables*: Are the pixels measured in the images. So the top left pixel is a variable, the bottom left pixel is a variable, and so on. So each pixel should be in a separate column. +2. *Measurements*: The measurements are the values for each pixel in each image. So each row corresponds to the values of the pixels for each row. +3. *Tables*: There would be two tables - one with the data from the pixels and one with the labels of each image (if we know them). + +To start to turn the image into a row of the data set we need to stretch the dots into a single row. One way to do this is to snake along the image going from top left corner to bottom right corner and creating a single line of dots. + + + +This still isn't quite data a computer can understand - a computer doesn't know about dots. But we could take each dot and label it with a color name. + + + +We could take each color name and give it a number, something like `rosybrown = 1`, `mistyrose = 2`, and so on. This approach runs into some trouble because we don't have names for every possible color and because it is pretty inefficient to have a different number for every hue we could imagine. + +But that would be both inefficient and not very understandable by a computer. An alternative strategy that is often used is to encode the intensity of the red, green, and blue colors for each pixel. This is sometimes called the rgb color model (Wikipedia contributors 2016b). So for example we can take these dots and show how much red, green, and blue they have in them. + + + +Looking at it this way we now have three measurements for each pixel. So we need to update our tidy data definition to be: + +1. *Variables*: Are the three colors for each pixel measured in the images. So the top left pixel red value is a variable, the top left pixel green value is a variable and so on. So each pixel/color combination should be in a separate column. +2. *Measurements*: The measurements are the values for each pixel in each image. So each row corresponds to the values of the pixels for each row. +3. *Tables*: There would be two tables - one with the data from the pixels and one with the labels of each image (if we know them). + +So a tidy data set might look something like this for just the image of Jeff. + +| id | label | p1red | p1green | p1blue | p2red | ... | +|-----|--------|-------|---------|--------|-------|-----| +| 1 | "jeff" | 238 | 180 | 180 | 205 | ... | + +Each additional image would then be another row in the data set. As we will see in the chapters that follow we can then feed this data into an algorithm for performing an artificial intelligence task. + +Notes +----- + +Parts of this chapter from appeared in the Simply Statistics blog post ["The vast majority of statistical analysis is not performed by statisticians"](http://simplystatistics.org/2013/06/14/the-vast-majority-of-statistical-analysis-is-not-performed-by-statisticians/) written by the author of this book. + +References +---------- + +Buhr, Sarah. 2017. “Illumina Wants to Sequence Your Whole Genome for $100.”The best way to have the stickiest and most lucrative product? Be a systematic tool for confirmation bias. https://t.co/8uOHZLomhX
— Kim-Mai Cutler (@kimmaicutler) November 10, 2016
 +
+Aunque existe la posibilidad de que la huelga ejerza suficiente presión política para que se responda a las exigencias determinadas en la asamblea, hay otras posibilidades menos favorables para los estudiantes:
+
+- La falta de actividad académica resulta en el exilio de miles de estudiantes a las universidades privadas.
+- La JSF usa el cierre para justificar aun más recortes: una institución no requiere millones de dolares al día si está cerrada.
+- Los recintos cerrados pierden su acreditación ya que una universidad en la cual no se da clases no puede cumplir con las [normas necesarias](http://www.msche.org/?Nav1=About&Nav2=FAQ&Nav3=Question07).
+- Se revocan las becas Pell a los estudiantes en receso.
+
+Hay mucha evidencia empírica que demuestra la importancia de la educación universitaria accesible. Lo mismo no es cierto sobre las huelgas como estrategia para defender dicha educación. Y cabe la posibildad que la huelga indefinida tenga el efecto opuesto y perjudique enormemente a los estudiantes, en particular a los que se ven forzados a matricularse en una universidad privada.
+
+
+Notas:
+
+1. Data proporcionada por el [Consejo de Educación de Puerto Rico (CEPR)](http://www2.pr.gov/agencias/cepr/inicio/estadisticas_e_investigacion/Pages/Estadisticas-Educacion-Superior.aspx).
+
+2. El costo del crédito del 2011 no incluye la cuota.
diff --git a/_posts/2017-04-06-march-for-science.md b/_posts/2017-04-06-march-for-science.md
new file mode 100644
index 0000000..62bb949
--- /dev/null
+++ b/_posts/2017-04-06-march-for-science.md
@@ -0,0 +1,13 @@
+---
+title: "Redirect"
+date: 2017-04-06
+author: rafa
+layout: post
+comments: true
+---
+
+This page was generated in error. The "Science really is non-partisan: facts and skepticism annoy everybody" blog post is [here](http://simplystatistics.org/2017/04/24/march-for-science/)
+
+Apologies for the inconvenience.
+
+
diff --git a/_posts/2017-04-24-march-for-science.md b/_posts/2017-04-24-march-for-science.md
new file mode 100644
index 0000000..ddad582
--- /dev/null
+++ b/_posts/2017-04-24-march-for-science.md
@@ -0,0 +1,33 @@
+---
+title: "Science really is non-partisan: facts and skepticism annoy everybody"
+date: 2017-04-24
+author: rafa
+layout: post
+comments: true
+---
+
+This is a short open letter to those that believe scientists have a “liberal bias” and question their objectivity. I suspect that for many conservatives, this Saturday’s March for Science served as confirmation of this fact. In this post I will try to convince you that this is not the case specifically by pointing out how scientists often annoy the left as much as the right.
+
+First, let me emphasize that scientists are highly appreciative of members of Congress and past administrations that have supported Science funding though the DoD, NIH and NSF. Although the current administration did propose a 20% cut to NIH, we are aware that, generally speaking, support for scientific research has traditionally been bipartisan.
+
+It is true that the typical data-driven scientists will disagree, sometimes strongly, with many stances that are considered conservative. For example, most scientists will argue that:
+
+1. Climate change is real and is driven largely by increased carbon dioxide and other human-made emissions into the atmosphere.
+2. Evolution needs to be part of children’s education and creationism has no place in Science class.
+3. Homosexuality is not a choice.
+4. Science must be publically funded because the free market is not enough to make science thrive.
+
+But scientists will also hold positions that are often criticized heavily by some of those who identify as politically left wing:
+
+1. Current vaccination programs are safe and need to be enforced: without heard immunity thousands of children would die.
+2. Genetically modified organisms (GMOs) are safe and are indispensable to fight world hunger. There is no need for warning labels.
+3. Using nuclear energy to power our electrical grid is much less harmful than using natural gas, oil and coal and, currently, more viable than renewable energy.
+4. Alternative medicine, such as homeopathy, naturopathy, faith healing, reiki, and acupuncture, is pseudo-scientific quackery.
+
+The timing of the announcement of the March for Science, along with the organizers’ focus on environmental issues and diversity, may have made it seem like a partisan or left-leaning event, but please also note that many scientists [criticized]( https://www.nytimes.com/2017/01/31/opinion/a-scientists-march-on-washington-is-a-bad-idea.html) the organizers for this very reason and there was much debate in general. Most scientists I know that went to the march did so not necessarily because they are against Republican administrations, but because they are legitimately concerned about some of the choices of this particular administration and the future of our country if we stop funding and trusting science.
+
+If you haven’t already seen this [Neil Degrasse Tyson video](https://www.youtube.com/watch?v=8MqTOEospfo) on the importance of Science to everyone, I highly recommend it.
+
+
+
+
diff --git a/_posts/2017-05-04-debt-haircuts.md b/_posts/2017-05-04-debt-haircuts.md
new file mode 100644
index 0000000..828a50e
--- /dev/null
+++ b/_posts/2017-05-04-debt-haircuts.md
@@ -0,0 +1,16 @@
+---
+title: "Some default and debt restructuring data"
+date: 2017-05-04
+author: rafa
+layout: post
+comments: true
+---
+
+Yesterday the government of Puerto Rico [asked for bankruptcy relief in federal court](https://www.nytimes.com/2017/05/03/business/dealbook/puerto-rico-debt.html). Puerto Rico owes about $70 billion to bondholders and about $50 billion in pension obligations. Before asking for protection the government offered to pay back some of the debt (50% according to some news reports) but bondholders refused. Bondholders will now fight in court to recover as much of what is owed as possible while the government and a federal oversight board will try to lower this amount. What can we expect to happen?
+
+A case like this is unprecedented, but there are plenty of data on restructurings. An [op-ed]( http://www.elnuevodia.com/opinion/columnas/ladeudaserenegociaraeneltribunal-columna-2317174/) by Juan Lara pointed me to [this]( http://voxeu.org/article/argentina-s-haircut-outlier) blog post describing data on 180 debt restructurings. I am not sure how informative these data are with regards to Puerto Rico, but the plot below sheds some light into the variability of previous restructurings. Colors represent regions of the world and the lines join points from the same country. I added data from US cases shown in [this paper](http://www.nfma.org/assets/documents/RBP/wp_statliens_julydraft.pdf).
+
+
+
+The cluster of points you see below the 30% mark appear to be cases involving particularly poor countries: Albania, Argentina, Bolivia, Ethiopia, Bosnia and Herzegovina, Guinea, Guyana, Honduras, Cameroon, Iraq, Congo, Rep., Costa Rica, Mauritania, Sao Tome and Principe, Mozambique, Senegal, Nicaragua, Niger, Serbia and Montenegro, Sierra Leone, Tanzania, Togo, Uganda, Yemen, and Republic of Zambia. Note also these restructurings happened after 1990.
+
diff --git a/html/midterm2012.html b/html/midterm2012.html
new file mode 100644
index 0000000..3ccc954
--- /dev/null
+++ b/html/midterm2012.html
@@ -0,0 +1,113 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+Aunque existe la posibilidad de que la huelga ejerza suficiente presión política para que se responda a las exigencias determinadas en la asamblea, hay otras posibilidades menos favorables para los estudiantes:
+
+- La falta de actividad académica resulta en el exilio de miles de estudiantes a las universidades privadas.
+- La JSF usa el cierre para justificar aun más recortes: una institución no requiere millones de dolares al día si está cerrada.
+- Los recintos cerrados pierden su acreditación ya que una universidad en la cual no se da clases no puede cumplir con las [normas necesarias](http://www.msche.org/?Nav1=About&Nav2=FAQ&Nav3=Question07).
+- Se revocan las becas Pell a los estudiantes en receso.
+
+Hay mucha evidencia empírica que demuestra la importancia de la educación universitaria accesible. Lo mismo no es cierto sobre las huelgas como estrategia para defender dicha educación. Y cabe la posibildad que la huelga indefinida tenga el efecto opuesto y perjudique enormemente a los estudiantes, en particular a los que se ven forzados a matricularse en una universidad privada.
+
+
+Notas:
+
+1. Data proporcionada por el [Consejo de Educación de Puerto Rico (CEPR)](http://www2.pr.gov/agencias/cepr/inicio/estadisticas_e_investigacion/Pages/Estadisticas-Educacion-Superior.aspx).
+
+2. El costo del crédito del 2011 no incluye la cuota.
diff --git a/_posts/2017-04-06-march-for-science.md b/_posts/2017-04-06-march-for-science.md
new file mode 100644
index 0000000..62bb949
--- /dev/null
+++ b/_posts/2017-04-06-march-for-science.md
@@ -0,0 +1,13 @@
+---
+title: "Redirect"
+date: 2017-04-06
+author: rafa
+layout: post
+comments: true
+---
+
+This page was generated in error. The "Science really is non-partisan: facts and skepticism annoy everybody" blog post is [here](http://simplystatistics.org/2017/04/24/march-for-science/)
+
+Apologies for the inconvenience.
+
+
diff --git a/_posts/2017-04-24-march-for-science.md b/_posts/2017-04-24-march-for-science.md
new file mode 100644
index 0000000..ddad582
--- /dev/null
+++ b/_posts/2017-04-24-march-for-science.md
@@ -0,0 +1,33 @@
+---
+title: "Science really is non-partisan: facts and skepticism annoy everybody"
+date: 2017-04-24
+author: rafa
+layout: post
+comments: true
+---
+
+This is a short open letter to those that believe scientists have a “liberal bias” and question their objectivity. I suspect that for many conservatives, this Saturday’s March for Science served as confirmation of this fact. In this post I will try to convince you that this is not the case specifically by pointing out how scientists often annoy the left as much as the right.
+
+First, let me emphasize that scientists are highly appreciative of members of Congress and past administrations that have supported Science funding though the DoD, NIH and NSF. Although the current administration did propose a 20% cut to NIH, we are aware that, generally speaking, support for scientific research has traditionally been bipartisan.
+
+It is true that the typical data-driven scientists will disagree, sometimes strongly, with many stances that are considered conservative. For example, most scientists will argue that:
+
+1. Climate change is real and is driven largely by increased carbon dioxide and other human-made emissions into the atmosphere.
+2. Evolution needs to be part of children’s education and creationism has no place in Science class.
+3. Homosexuality is not a choice.
+4. Science must be publically funded because the free market is not enough to make science thrive.
+
+But scientists will also hold positions that are often criticized heavily by some of those who identify as politically left wing:
+
+1. Current vaccination programs are safe and need to be enforced: without heard immunity thousands of children would die.
+2. Genetically modified organisms (GMOs) are safe and are indispensable to fight world hunger. There is no need for warning labels.
+3. Using nuclear energy to power our electrical grid is much less harmful than using natural gas, oil and coal and, currently, more viable than renewable energy.
+4. Alternative medicine, such as homeopathy, naturopathy, faith healing, reiki, and acupuncture, is pseudo-scientific quackery.
+
+The timing of the announcement of the March for Science, along with the organizers’ focus on environmental issues and diversity, may have made it seem like a partisan or left-leaning event, but please also note that many scientists [criticized]( https://www.nytimes.com/2017/01/31/opinion/a-scientists-march-on-washington-is-a-bad-idea.html) the organizers for this very reason and there was much debate in general. Most scientists I know that went to the march did so not necessarily because they are against Republican administrations, but because they are legitimately concerned about some of the choices of this particular administration and the future of our country if we stop funding and trusting science.
+
+If you haven’t already seen this [Neil Degrasse Tyson video](https://www.youtube.com/watch?v=8MqTOEospfo) on the importance of Science to everyone, I highly recommend it.
+
+
+
+
diff --git a/_posts/2017-05-04-debt-haircuts.md b/_posts/2017-05-04-debt-haircuts.md
new file mode 100644
index 0000000..828a50e
--- /dev/null
+++ b/_posts/2017-05-04-debt-haircuts.md
@@ -0,0 +1,16 @@
+---
+title: "Some default and debt restructuring data"
+date: 2017-05-04
+author: rafa
+layout: post
+comments: true
+---
+
+Yesterday the government of Puerto Rico [asked for bankruptcy relief in federal court](https://www.nytimes.com/2017/05/03/business/dealbook/puerto-rico-debt.html). Puerto Rico owes about $70 billion to bondholders and about $50 billion in pension obligations. Before asking for protection the government offered to pay back some of the debt (50% according to some news reports) but bondholders refused. Bondholders will now fight in court to recover as much of what is owed as possible while the government and a federal oversight board will try to lower this amount. What can we expect to happen?
+
+A case like this is unprecedented, but there are plenty of data on restructurings. An [op-ed]( http://www.elnuevodia.com/opinion/columnas/ladeudaserenegociaraeneltribunal-columna-2317174/) by Juan Lara pointed me to [this]( http://voxeu.org/article/argentina-s-haircut-outlier) blog post describing data on 180 debt restructurings. I am not sure how informative these data are with regards to Puerto Rico, but the plot below sheds some light into the variability of previous restructurings. Colors represent regions of the world and the lines join points from the same country. I added data from US cases shown in [this paper](http://www.nfma.org/assets/documents/RBP/wp_statliens_julydraft.pdf).
+
+
+
+The cluster of points you see below the 30% mark appear to be cases involving particularly poor countries: Albania, Argentina, Bolivia, Ethiopia, Bosnia and Herzegovina, Guinea, Guyana, Honduras, Cameroon, Iraq, Congo, Rep., Costa Rica, Mauritania, Sao Tome and Principe, Mozambique, Senegal, Nicaragua, Niger, Serbia and Montenegro, Sierra Leone, Tanzania, Togo, Uganda, Yemen, and Republic of Zambia. Note also these restructurings happened after 1990.
+
diff --git a/html/midterm2012.html b/html/midterm2012.html
new file mode 100644
index 0000000..3ccc954
--- /dev/null
+++ b/html/midterm2012.html
@@ -0,0 +1,113 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+Nate Silver does a great job of explaining his forecast model to laypeople. However, as a statistician I’ve always wanted to know more details. After preparing a “predict the midterm elections” homework for my data science class I have a better idea of what is going on. Here is my current best explanation of the model that motivates the way they create a posterior distribution for the election day result. Note: this was written in a couple of hours and may include mistakes.
+Let \(\theta\) represents the real difference between the republican and democrat candidate on election day. The naive approach used by individual pollsters is to obtain poll data and construct a confidence interval. For example by using the normal approximation to the binomial distribution we can write:
+\[Y = \theta + \varepsilon \mbox{ with } \varepsilon \sim N(0,\sigma^2)\]
+with \(\sigma^2\) inversely proportional to the number of people polled. One of the most important insights made by poll aggregators is that this assumption underestimates the variance introduced by pollster effects (also referred to as house effects) as demonstrated by the plot below. For polls occurring within 1 week of the 2010 midterm election this plot shows the difference between individual predictions and the actual outcome of each race stratified by pollster.
+
The model can be augmented to \[Y_{i,j} = \theta + h_i + \varepsilon_{i,j} \mbox{ for polls } i=1\dots,M \mbox{ and } j \mbox{ an index representing days left until election}\]
+Here \(h_i\) represents random pollster effect. Another important insight is that by averaging these polls the estimator’s variance is reduced and that we can estimate the across pollster variance from data. Note that to estimate \(\theta\) we need an assumption such as \(\mbox{E}(h_i)=0\). More on this later. Also note that we can model the pollster specific effects to have different variances. To estimate these we can use previous election. With these in place, we can construct weighted estimates for \(\theta\) that down-weight bad pollsters.
+This model is still insufficient as it ignores another important source of variability: time. In the figure below we see data from the Minnesota 2000 senate race. Note that had we formed a confidence interval, based on aggregated data (different colors represent different pollsters), 20 days before the election we would have been quite certain that the republican was going to win when in fact the democrat won (red X marks the final result). Note that the 99% confidence interval we formed with 20 days before the election was not for \(\theta\) but for \(\theta\) plus some day effect.
+
There was a well documented internet feud in which Nate Silver explained why Princeton Election Consortium snapshot predictions were overconfident because they ignored this source of variability. We therefore augment the model to
+\[Y_{i,j} = \theta + h_i + d_j + \varepsilon_{i,j}\]
+with \(d_j\) the day effect. Although we can model this as a fixed effect and estimate it with, for example, loess, this is not that useful for forecasting as we don’t know if the trend will continue. More useful is to model it as a random effect with its variance depending on days left to the election. The plot below, shows the residuals for the Rasmussen pollster, and motivates the need to model a decreasing variance. Note that we also want to assume \(d\) is an auto-correlated process.
+
If we apply this model to current data we obtain confidence intervals that are generally smaller than those implied by the current 538 forecast. This is because there are general biases that we have not accounted for. Specifically our assumption that \(\mbox{E}(h_i)=0\) is incorrect. This assumption says that, on average, pollsters are not biased, but this is not the case. Instead we need to add a general bias to the model
+\[Y_{i,j} = \theta + h_i + d_j + b + \varepsilon_{i,j}.\]
+But note we can’t estimate \(b\) from the data: this model is not identifiable. However, we can model \(b\) as a random effect with and estimate it’s variance from past elections where we know \(\theta\). Here is a plot of residuals that give us an idea of the values \(b\) can take. Note that the standard deviation of the yearly average bias is about 2. This means that the SE has a lower bound: even with data from \(\infty\) polls we should not assume our estimates have SE lower than 2.
+
Here is a specific example where this bias resulted in all polls being wrong. Note where the red X is.
+
Note that, despite these polls predicting a clear victory for Angle, 538 only gave her a 83% of winning. They must be including some extra variance term as our model above does. Also note, that we have written a model for one state. In a model including all states we could include a state-specific \(b\) as well as a general \(b\).
+Finally, most of the aggregaors report statements that treat \(\theta\) as random. For example, they report the probability that the republican candidate will win \(\mbox{Pr}(\theta>0 | Y)\). This implies a prior distribution is set: \(\theta \sim N(\mu,\tau^2)\). As Nate Silver explained, 538 uses fundamentals to decide \(\mu\) while \(\tau\) can be deduced from the weight that fundamentals are given in the light of poll data:
+++“This works by treating the state fundamentals estimate as equivalent to a “poll” with a weight of 0.35. What does that mean? Our poll weights are designed such that a 600-voter poll from a firm with an average pollster rating gets a weight of 1.00 (on the day of its release55; this weight will decline as the poll ages). Only the lowest-rated pollsters will have a weight as low as 0.35. So the state fundamentals estimate is treated as tantamount to a single bad (though recent) poll. This differs from the presidential model, where the state fundamentals estimate is more reliable and gets a considerably heavier weight.”
+
I assume they used training/testing approaches to decide on this value of \(\tau\). But also note that it does not influence the final result of races with many polls. For example, note that for a race with 25 polls, the data receives about 99% of the weight making the posterior practically equivalent to the sampling distribution.
+Finally, because the tails of the normal distribution are not fat enough to account for the upsets we occasionally see, 538 uses the Fleishman’s Transformation to increase these probabilities.
+We have been discussing these ideas in class and part of the homework was to predict the number of republican senators. Here are few example example. The student that provides the smallest interval that includes the result wins (this explains why some took the risky approach of a one number interval). In a few hours we will know how well they did.
+